Breaking Eggs And Making Omelettes
A blog dealing with technical multimedia matters, binary reverse engineering, and the occasional video game hacking.
Les articles publiés sur le site
-
Alias Artifacts
26 avril 2013, par Multimedia Mike — GeneralThroughout my own life, I have often observed that my own sense of nostalgia has a window that stretches about 10-15 years past from the current moment. Earlier this year, I discovered the show “Alias” and watched through the entire series thanks to Amazon Prime Instant Video (to be fair, I sort of skimmed the fifth and final season which I found to be horribly dull, or maybe franchise fatigue had set in). The show originally aired from 2001-2006 so I found that it fit well within the aforementioned nostalgia window.

But what was it, exactly, about the show that triggered nostalgia? The computers, of course! The show revolved around spies and espionage and cutting-edge technology necessarily played a role. The production designer for the series must have decided that Unix/Linux == awesome hacking and so many screenshots featured Linux.
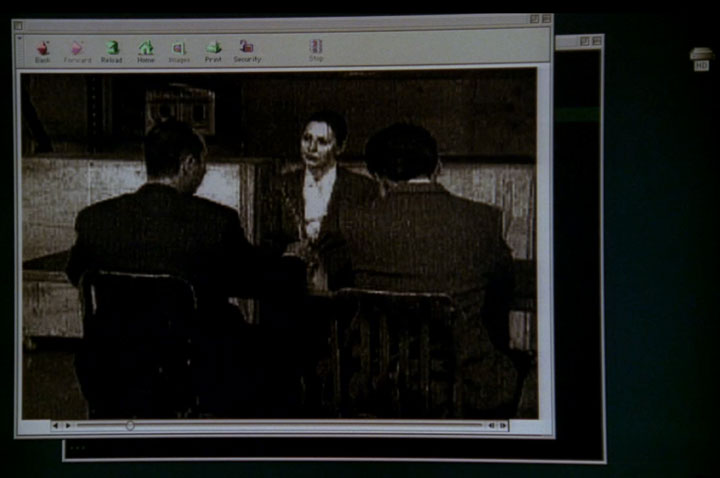
Since this is still nominally a multimedia blog, I’ll start of the screenshot recon with an old multimedia player. Here is a vintage Mac OS desktop running an ancient web browser (probably Netscape) that’s playing a full-window video (probably QuickTime embedded directly into the browser).

Click for larger image
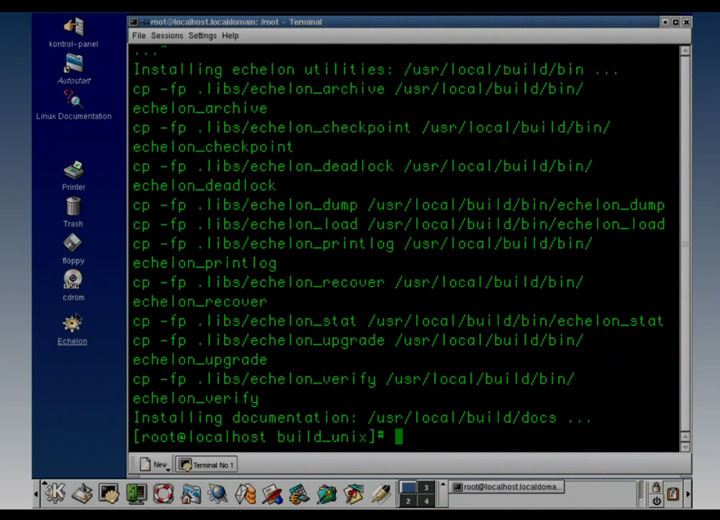
Let’s jump right into the Linux side of things. This screenshot makes me particularly sentimental since this is exactly what a stock Linux/KDE desktop looked like circa 2001-2003 and is more or less what I would have worked with on my home computer at the time:

Click for larger image
Studying that screenshot, we see that the user logs in as root, even to the desktop environment. Poor security practice; I would expect better from a bunch of spooks.
Echelon
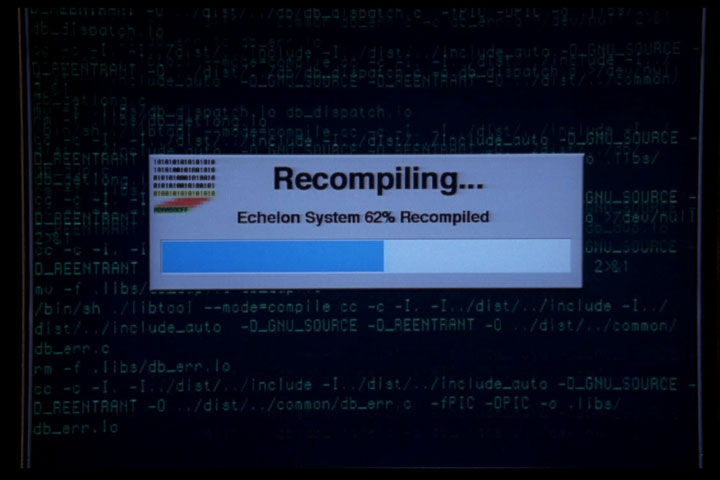
Look at the terminal output in the above screenshot– it’s building a program named Echelon, an omniscient spy tool inspired by a real-world surveillance network of the same name. In the show, Echelon is used to supply plot-convenient intelligence. At one point, some antagonists get their hands on the Echelon source code and seek to compile it. When they do, they will have access to the vast surveillance network. If you know anything about how computers work, don’t think about that too hard.Anyway, it’s interesting to note that Echelon is a properly autotool’d program– when the bad guys finally got Echelon, installation was just a ‘make install’ command away. The compilation was very user-friendly, though, as it would pop up a nice dialog box showing build progress:

Click for larger image
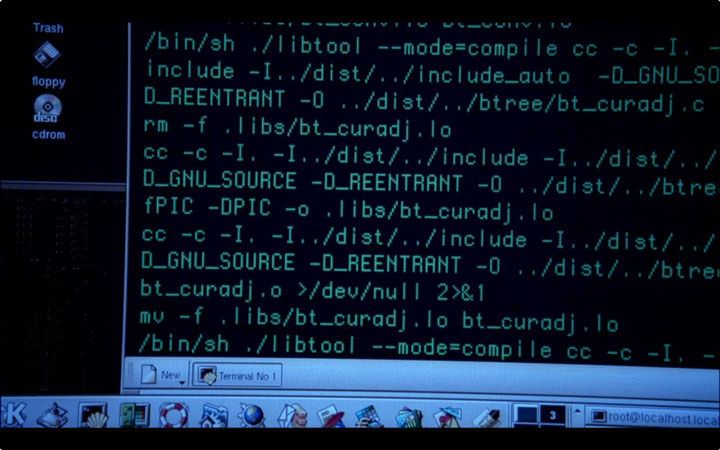
Examining the build lines in both that screenshot and the following lines, we can see that Echelon cares about files such as common/db_err.c and bt_curadj.c:

Click for larger image
A little googling reveals that these files both belong to the Berkeley DB library. That works; I can imagine a program like this leveraging various database packages.
Computer Languages
The Echelon source code stuff comes from episode 2.11: “A Higher Echelon”. While one faction had gotten a hold of the actual Echelon source code, a rival faction had abducted the show’s resident uber-nerd and, learning that they didn’t actually receive the Echelon code, force the nerd to re-write Echelon from scratch. Which he then proceeds to do…

Click for larger image
The code he’s examining there appears to be C code that has something to do with joystick programming (JS_X_0, JS_Y_1, etc.). An eagle-eyed IMDb user contributed the trivia that he is looking at the file /usr/include/Linux/joystick.h.
Getting back to the plot, how could the bad buys possibly expect him to re-write a hugely complex piece of software from scratch? You might think this is the height of absurdity for a computer-oriented story. You’ll be pleased to know that the writers agreed with that assessment since, when the program was actually executed, it claimed to be Echelon, but that broke into a game of Pong (or some simple game). Suddenly, it makes perfect sense why the guy was looking at the joystick header file.
This is the first bit of computer-oriented fun that I captured when I was watching the series:

Click for larger image
This printout purports to be a “mainframe log summary”. After some plot-advancing text about a security issue, it proceeds to dump out some Java source code.
SSH
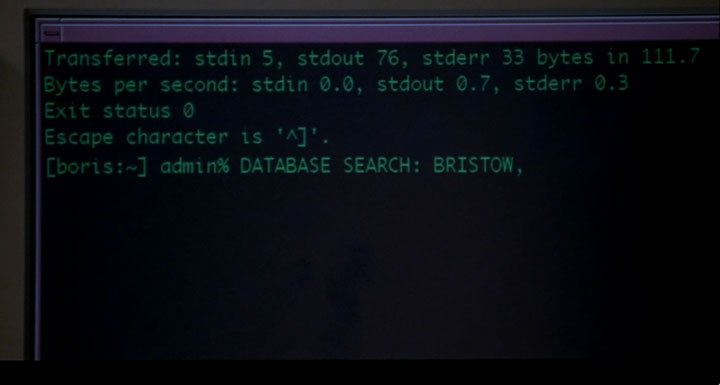
Secure Shell (SSH) frequently showed up. Here’s a screenshot in which a verbose ‘ssh -v’ connection has just been closed, while a telnet command has apparently just been launched (evidenced by “Escape character is ‘^]’.”):

Click for larger image
This is followed by some good old Hollywood Hacking in which a free-form database command is entered through any available command line interface:

Click for larger image
I don’t remember the episode details, but I’m pretty sure the output made perfect sense to the character typing the command. Here’s another screenshot where the SSH client pops up an extra-large GUI dialog element to notify the user that it’s currently negotiating with the host:

Click for larger image
Now that I look at that screenshot a little more closely, it appears to be a Win95/98 program. I wonder if there was an SSH client that actually popped up that gaudy dialog.
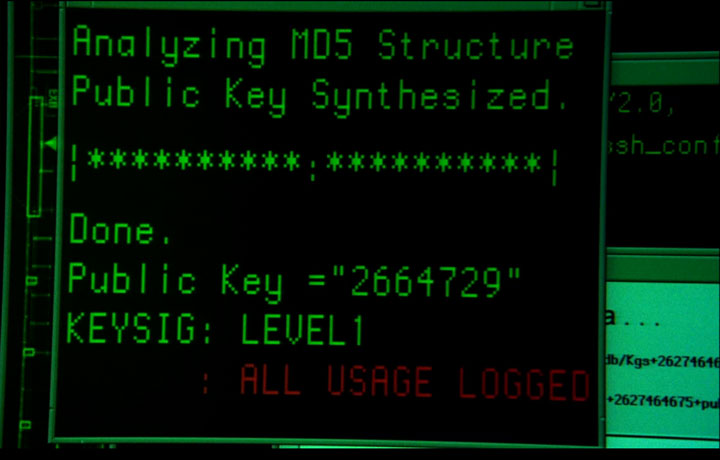
There’s a lot of gibberish in this screenshot and I wish I had written down some details about what it represented according to the episode’s plot:

Click for larger image
It almost sounds like they were trying to break into a network computer. Analyzing MD5 structure… public key synthesized. To me, the funniest feature is the 7-digit public key. I’m a bit rusty on the math of the RSA cryptosystem, but intuitively, it seems that the public and private keys need to be of roughly equal lengths. I.e., the private key in this scenario would also be 7 digits long.
Gadgets
Various devices and gadgets were seen at various junctures in the show. Here’s a tablet computer from back when tablet computers seemed like fantastical (albeit stylus-requiring) devices– the Fujitsu Stylistic 2300:

Click for larger image
Here’s a videophone from an episode that aired in 2005. The specific model is the Packet8 DV326 (MSRP of US$500). As you can see from the screenshot, it can do 384 kbps both down and up.

Click for larger image
I really regret not writing down the episode details surrounding this gadget. I just know that it was critical that the good guys get it and keep from falling into the hands of the bad guys.

Click for larger image
As you can see, the (presumably) deadly device contains a Samsung chip and a Lexar chip. I have to wonder what device the production crew salvaged this from (probably just an old cell phone).
Other Programs
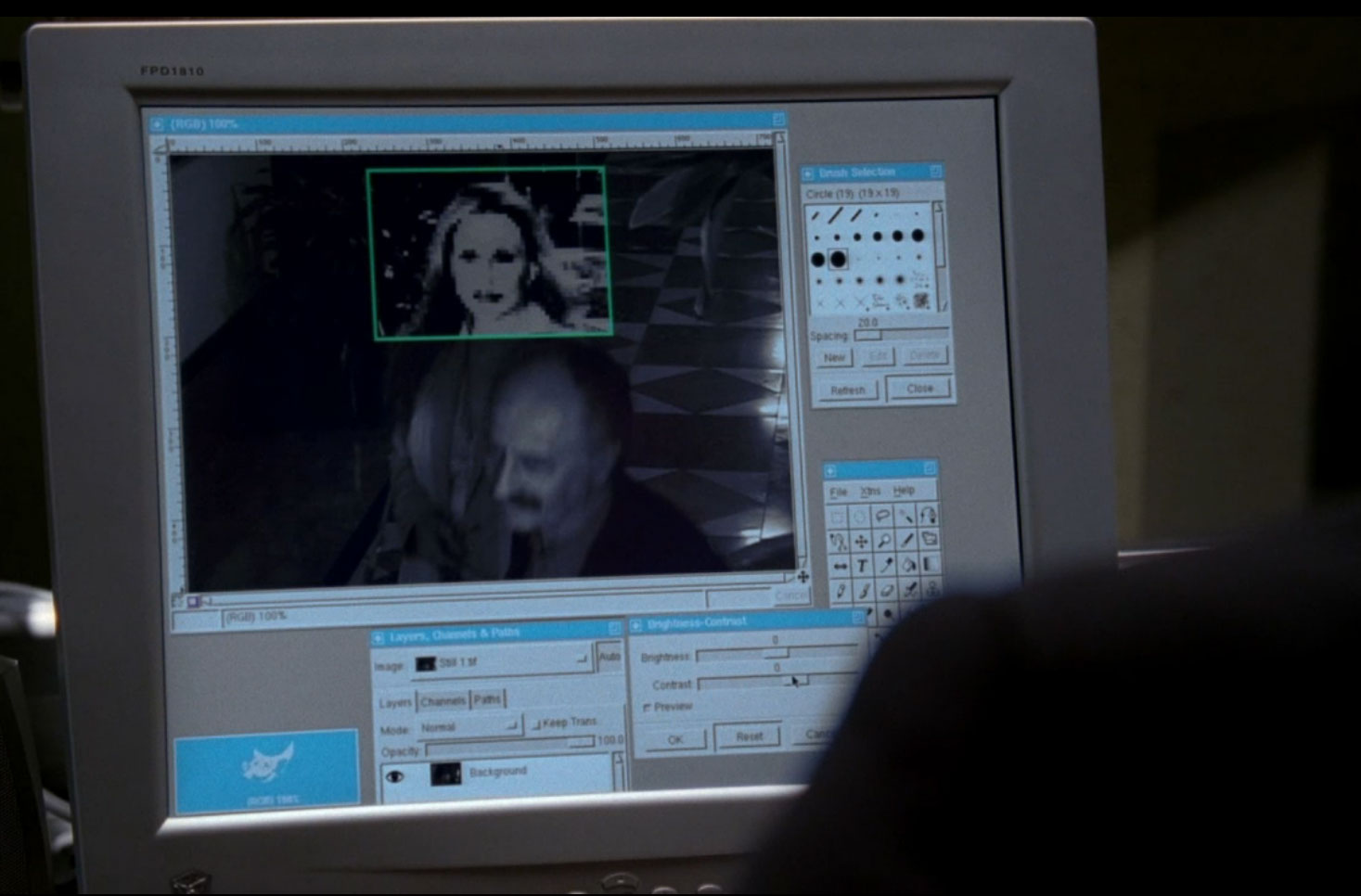
The GIMP photo editor makes an appearance while scrubbing security camera footage, and serves as the magical Enhance Button (at least they slung around the term “gamma”):

Click for larger image
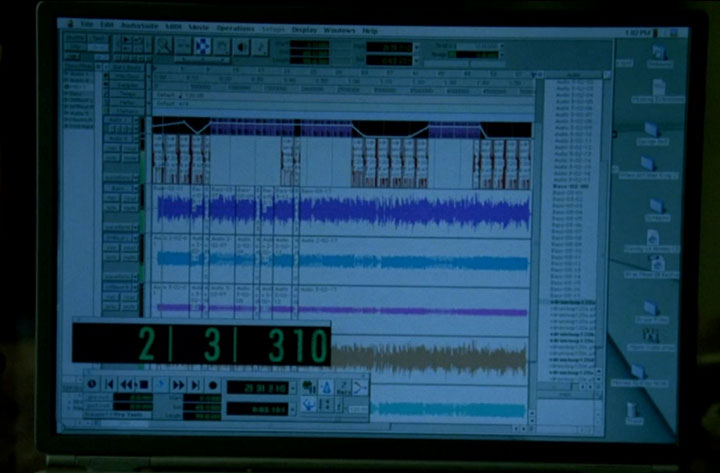
I have no idea what MacOS-based audio editing program this is. Any ideas?

Click for larger image
FTP shows up in episode 2.12, “The Getaway”. It’s described as a “secure channel” for communication, which is quite humorous to anyone versed in internet technology.

Click for larger image
-
Elacarte Presto Tablets
14 mars 2013, par Multimedia Mike — GeneralI visited an Applebee’s restaurant this past weekend. The first thing I spied was a family at a table with what looked like a 7-inch tablet. It’s not an uncommon sight. However, as I moved through the restaurant, I noticed that every single table was equipped with such a tablet. It looked like this:

For a computer nerd like me, you could probably guess that I was be far more interested in this gadget than the cuisine. The thing said “Presto” on the front and “Elacarte” on the back. Putting this together, we get the website of Elacarte, the purveyors of this restaurant tablet technology. Months after the iPad was released on 2010, I remember stories about high-end restaurants showing their wine list via iPads. This tablet goes well beyond that.
How was it? Well, confusing, mostly. The hostess told us we could order through the tablet or through her. Since we already knew what we wanted, she just manually took our order and presumably entered it into the system. So, right away, the question is: Do we order through a human or through a computer? Or a combination? Do we have to use the tablet if we don’t want to?
Hardware
When picking up the tablet, it’s hard not to notice that it is very heavy. At first, I suspected that it was deliberately weighted down as some minor attempt at an anti-theft measure. But then I remembered what I know about power budgets of phones and tablets– powering the screen accounts for much of the battery usage. I realized that this device needs to drive the screen for about 14 continuous hours each day. I.e., the weight must come from a massive battery.The screen is good. It’s a capacitive touchscreen, so nice and responsive. When I first spied the device, I felt certain it would be a resistive touchscreen (which is more accurately called a touch-and-press-down screen). There is an AC adapter on the side of the tablet. This is the only interface to the device:

That looks to me like an internal SATA connector (different from an eSATA connector). Foolishly, I didn’t have a SATA cable on me so I couldn’t verify.
User Interface
The interface options are: Order, Games, Neighborhood, and Pay. One big benefit of accessing the menu through the Order option is that each menu item can have a picture. For people who order more by picture than text description, this is useful. Rather, it would be, if more items had pictures. I’m not sure there were more pictures than seen in the print menu.
For Games, there were a variety of party games. The interface clearly stated that we got to play 2 free games. This implied to me that further games cost money. We tried one game briefly and the food came.2 more options: Neighborhood– I know I dug into this option, but I forget what it was. Maybe it discussed local attractions. Finally, Pay. This thing has an integrated credit card reader. There is no integrated printer, though, so if you want one, you will have to request one from a human.
Experience
So we ordered through a human since we didn’t feel like being thrust into this new paradigm when we just wanted lunch. The staff was obviously amenable to that. However, I got a chance to ask them a lot of questions about the particulars. Apparently, they have had this system for about 5 months. It was confirmed that the tablets do, in fact, have gargantuan batteries that have to last through the restaurant’s entire business hours. Do they need to be charged every night? Yes, they do. But how? The staff described this several large charging blocks with many cables sprouting out. Reportedly, some units still don’t make it through the entire day.When it was time to pay, I pressed the Pay button on the interface. The bill I saw had nothing in common with what we ordered (actually, it was cheaper, so perhaps I should have just accepted it). But I pointed it out to a human and they said that this happens sometimes. So they manually printed my bill. There was a dollar charge for the game that was supposed to be free. I pointed this out and they removed it. It’s minor, I know, but it’s still worth trying to work out these bugs.
One of the staff also described how a restaurant doesn’t need to employ as many people thanks to the tablet. She gave a nervous, awkward, self-conscious laugh when she said this. All I could think of was this Dilbert comic strip in which the boss realizes that his smartphone could perform certain key functions previously handled by his assistant.
Not A New Idea
Some people might think this is a totally new concept. It’s not. I was immediately reminded of my university days in Boulder, Colorado, USA, circa 1997. The local Taco Bell and Arby’s restaurants both had touchscreen ordering kiosks. Step up, interact with the (probably resistive) touchscreen, get a number, and step to the counter to change money, get your food, and probably clarify your order because there is only so much that can be handled through a touchscreen.What I also remember is when they tore out those ordering kiosks, also circa 1997. I don’t know the exact reason. Maybe people didn’t like them. Maybe there were maintenance costs that made them not worth the hassle.
Then there are the widespread self-checkout lanes in grocery stores. Personally, I like those, though I know many don’t. However, this restaurant tablet thing hasn’t won me over yet. What’s the difference? Perhaps that automated lanes at grocery stores require zero external assistance– at least, if you do everything correctly. Personally, I work well with these lanes because I can pretty much guess the constraints of the system and I am careful not to confuse the computer in any way. Until they deploy serving droids, or at least food conveyors, there still needs to be some human interaction and I think the division between the human and computer roles is unintuitive in the restaurant case.
I don’t really care to return to the same restaurant. I’ll likely avoid any other restaurant that has these tablets. For some reason, I think I’m probably supposed to be the ideal consumer of this concept. But the idea will probably perform all right anyway. Elacarte’s website has plenty of graphs demonstrating that deploying these tablets is extremely profitable.
-
Investigating Steam for Linux
1er mars 2013, par Multimedia Mike — Game HackingValve recently released the final, public version of their Steam client for Linux, and the Linux world rejoiced. At least, it probably did. The announcement was 2 weeks ago on Valentine’s Day and I had other things on my mind, so I missed any fanfare. When framed in this manner, the announcement timing becomes suspect– it’s as though Linux enthusiasts would have plenty of time that day or something.

Taming the Frontier
Speculation about a Linux Steam client had been kicking around for nearly as long as Steam has existed. However, sometime last year, the rumors became more substantive.I naturally wondered how to port something like Steam to Linux. I have some experience with trying to make a necessarily binary-only program that runs on Linux. I’m fairly well-versed in the assorted technical challenges that one might face when attempting such a feat. Because of this, whenever I hear rumors that a company might be entertaining the notion of porting a major piece of proprietary software to Linux, my instinctive reflex is, “What?! Why, you fools?! Save yourselves!”
At least, that’s how it used to be. The proposal of developing a proprietary binary for Linux has been rendered considerably less insane by a few developments, for example:
- The rise of Ubuntu Linux as a quasi de facto standard for desktop Linux computing
- The increasing homogeneity in personal desktop computing technology
What I would like to know is how the Steam client runs on Linux. Does it rely on any libraries being present on the system? Or does it bring its own? The latter is a trick that proprietary programs can use– transport all of the shared libraries that the main program binary depends upon, install them someplace out of the way on the filesystem, probably in /opt, and then make the main program a shell script which sets a preload path to rely on the known quantity libraries instead of the copies already on the system.
Downloading and Installing the Client
For this exercise, I installed x86_64 desktop Ubuntu 12.04 Linux on a l33t gaming rig that was totally top of the line about 5 years ago, and that someone didn’t want anymore and handed down to me recently. So it should be ideal for this project.At first, I was blown away– the Linux client is in a .deb package that is less than 2 MB large. I unpacked the steam.deb file and found a bunch of support libraries — mostly X11 and standard C/C++ runtimes. Just as I suspected. Still, I can’t believe how small the thing is. However, my amazement quickly abated when I actually ran Steam and saw this:

So it turns out steam.db is just the installer program which immediately proceeds to download an additional 160+ MB of data. So there’s actually a lot more information to possibly sift through.
Another component of the installation is to basically run a big ‘apt-get install’ command to make sure a bunch of required packages are installed:

After all these installation steps, the client was ready to run. However, whenever I tried to do so, I got this dialog which would cause Steam to close when the dialog was dismissed.

Not a huge deal; later NVIDIA drivers are fairly straightforward to install on Ubuntu Linux. After a few minutes of downloading, installing and restarting X, Steam ran with minimal complaint (it still had some issue regarding the video drivers but didn’t seem to consider it a deal-breaker).
Using Steam on Linux
So here’s Steam running on Linux:

If you have experience with using Steam on Windows or Mac, you might observe that it looks exactly the same. I don’t have a very expansive library of games (I only started using Steam because purchasing a few computer components a few years ago entitled me to some free Steam downloads of some of the games on the list in the screenshot). I didn’t really expect any of the games to have Linux versions yet, but it turns out that the indie darling FTL: Faster Than Light has been ported to Linux. FTL was a much-heralded Kickstarter success story and sounded like something I wanted to support. I purchased this from Steam shortly after its release last year and was able to download the Linux version at no additional cost with a single click.
It runs natively on Linux (note the Ubuntu desktop window decorations):

You might notice from the main Steam client that, despite purchasing FTL about a 1/2 year ago and starting it up at least a 1/2 dozen times, I haven’t really invested a whole lot of time into it. I only managed to get about 2 minutes further this time:

What can I say? This game just bores me to tears. It’s frustrating because I know that this is one of the cool games that all real gamers are supposed to like, but I practically catch myself nodding off every time I try to run through the tutorial. It’s strange to think that I’ve invested far more time into games that offer considerably less stimulation. That’s probably because I had far more free time compared to gaming options during those times.
But that’s neither here nor there. We’ll file this under “games that aren’t for me.” I’m glad that people like FTL and a little indie underdog has met with such success. And I’m pleased that Steam on Linux works. It’s native and the games are also native, which is all quite laudable (there was speculation that everything would just be running on top of a Wine layer).
Deeper Analysis
So I set out wondering how Steam was able to create a proprietary program that would satisfy a large enough cross-section of Linux users (i.e., on different platforms and distros). Answer: well, they didn’t, per the stated requirements. The installation is only tuned to work on Ubuntu 12.04. However, it works on both 32- and 64-bit platforms, the only 2 desktop CPU platforms that matter these days (unless ARM somehow makes inroads on the desktop). The Steam client is quite clearly an x86_32 binary– look at the terminal screenshot above and observe that it’s downloading all :i386 support libraries.The file /usr/bin/steam isn’t a binary but a launcher shell script (something you’ll also see if you investigate /usr/bin/firefox on a Linux system). Here’s an interesting tidbit:
function detect_platform() { # Maybe be smarter someday # Right now this is the only platform we have a bootstrap for, so hard-code it. echo ubuntu12_32 }I wager that it’s possible to get Steam running on other distributions, it probably just takes a little more effort (assuming that Steam doesn’t put too much effort into thwarting such attempts).
As for the FTL game, it comes with binaries and libraries for both x86_32 and x86_64. So, good work to the dev team for creating and testing both versions. FTL also distributes versions of the libraries it expects to work with.
I suspect that the Steam client overall is largely a WWW rendering engine underneath the covers. That would help explain how Valve is able to achieve such a consistent look and feel, not only across OS platforms, but also through a web browser. When I browse the Steam store through Google Chrome, it looks and feels exactly like the native desktop client. When I first thought of how someone could port Steam to Linux, I immediately wondered about how they would do the UI.
A little Googling for “steam uses webkit” (just a hunch) confirms my hypothesis.
-
Grand Unified Theory of Compact Disc
1er février 2013, par Multimedia Mike — GeneralThis is something I started writing about a decade ago (and I almost certainly have some of it wrong), back when compact discs still had a fair amount of relevance. Back around 2002, after a few years investigating multimedia technology, I took an interest in compact discs of all sorts. Even though there may seem to be a wide range of CD types, I generally found that they’re all fundamentally the same. I thought I would finally publishing something, incomplete though it may be.
Physical Perspective
There are a lot of ways to look at a compact disc. First, there’s the physical format, where a laser detects where pits/grooves have disturbed the smooth surface (a.k.a. lands). A lot of technical descriptions claim that these lands and pits on a CD correspond to ones and zeros. That’s not actually true, but you have to decide what level of abstraction you care about, and that abstraction is good enough if you only care about the discs from a software perspective.Grand Unified Theory (Software Perspective)
Looking at a disc from a software perspective, I have generally found it useful to view a CD as a combination of a 2 main components:- table of contents (TOC)
- a long string of sectors, each of which is 2352 bytes long
I like to believe that’s pretty much all there is to it. All of the information on a CD is stored as a string of sectors that might be chopped up into a series of anywhere from 1-99 individual tracks. The exact sector locations where these individual tracks begin are defined in the TOC.
Audio CDs (CD-DA / Red Book)
The initial purpose for the compact disc was to store digital audio. The strange sector size of 2352 bytes is an artifact of this original charter. “CD quality audio”, as any multimedia nerd knows, is formally defined as stereo PCM samples that are each 16 bits wide and played at a frequency of 44100 Hz.
(44100 audio frames / 1 second) * (2 samples / audio frame) * (16 bits / 1 sample) * (1 byte / 8 bits) = 176,400 bytes / second (176,400 bytes / 1 second) / (2352 bytes / 1 sector) = 75
75 is the number of sectors required to store a single second of CD-quality audio. A single sector stores 1/75th of a second, or a ‘frame’ of audio (though I think ‘frame’ gets tossed around at all levels when describing CD formats).
The term “red book” is thrown around in relation to audio CDs. There is a series of rainbow books that define various optical disc standards and the red book describes audio CDs.
Basic Data CD-ROMs (Mode 1 / Yellow Book)
Somewhere along the line, someone decided that general digital information could be stored on these discs. Hence, the CD-ROM was born. The standard model above still applies– TOC and string of 2352-byte sectors. However, it’s generally only useful to have a single track on a CD-ROM. Thus, the TOC only lists a single track. That single track can easily span the entire disc (something that would be unusual for a typical audio CD).While the model is mostly the same, the most notable difference between and audio CD and a plain CD-ROM is that, while each sector is 2352 bytes long, only 2048 bytes are used to store actual data payload. The remaining bytes are used for synchronization and additional error detection/correction.
At least, the foregoing is true for mode 1 / form 1 CD-ROMs (which are the most common). “Mode 1″ CD-ROMs are defined by a publication called the yellow book. There is also mode 1 / form 2. This forgoes the additional error detection and correction afforded by form 1 and dedicates 2336 of the 2352 sector bytes to the data payload.
CD-ROM XA (Mode 2 / Green Book)
From a software perspective, these are similar to mode 1 CD-ROMs. There are also 2 forms here. The first form gives a 2048-byte data payload while the second form yields a 2324-byte data payload.Video CD (VCD / White Book)
These are CD-ROM XA discs that carry MPEG-1 video and audio data.Photo CD (Beige Book)
This is something I have never personally dealt with. But it’s supposed to conform to the CD-ROM XA standard and probably fits into my model. It seems to date back to early in the CD-ROM era when CDs were particularly cost prohibitive.Multisession CDs (Blue Book)
Okay, I admit that this confuses me a bit. Multisession discs allow a user to burn multiple sessions to a single recordable disc. I.e., burn a lump of data, then burn another lump at a later time, and the final result will look like all the lumps were recorded as the same big lump. I remember this being incredibly useful and cost effective back when recordable CDs cost around US$10 each (vs. being able to buy a spindle of 100 CD-Rs for US$10 or less now). Studying the cdrom.h file for the Linux OS, I found a system call named CDROMMULTISESSION that returns the sector address of the start of the last session. If I were to hypothesize about how to make this fit into my model, I might guess that the TOC has some hint that the disc was recorded in multisession (which needs to be decided up front) and the CDROMMULTISESSION call is made to find the last session. Or it could be that a disc read initialization operation always leads off with the CDROMMULTISESSION query in order to determine this.I suppose I could figure out how to create a multisession disc with modern software, or possibly dig up a multisession disc from 15+ years ago, and then figure out how it should be read.
CD-i
This type puzzles my as well. I do have some CD-i discs and I thought that I could read them just fine (the last time I looked, which was many years ago). But my research for this blog post has me thinking that I might not have been seeing the entire picture when I first studied my CD-i samples. I was able to see some of the data, but sources indicate that only proper CD-i hardware is able to see all of the data on the disc (apparently, the TOC doesn’t show all of the sectors on disc).Hybrid CDs (Data + Audio)
At some point, it became a notable selling point for an audio CD to have a data track with bonus features. Even more common (particularly in the early era of CD-ROMs) were computer and console games that used the first track of a disc for all the game code and assets and the remaining tracks for beautifully rendered game audio that could also be enjoyed outside the game. Same model: TOC points to the various tracks and also makes notes about which ones are data and which are audio.There seems to be 2 distinct things described above. One type is the mixed mode CD which generally has the data in the first track and the audio in tracks 2..n. Then there is the enhanced CD, which apparently used multisession recording and put the data at the end. I think that the reasoning for this is that most audio CD player hardware would only read tracks from the first session and would have no way to see the data track. This was a positive thing. By contrast, when placing a mixed-mode CD into an audio player, the data track would be rendered as nonsense noise.
Subchannels
There’s at least one small detail that my model ignores: subchannels. CDs can encode bits of data in subchannels in sectors. This is used for things like CD-Text and CD-G. I may need to revisit this.In Summary
There’s still a lot of ground to cover, like how those sectors might be formatted to show something useful (e.g., filesystems), and how the model applies to other types of optical discs. Sounds like something for another post. -
What Every Programmer Should Know
24 décembre 2012, par Multimedia Mike — GeneralDuring my recent effort to force myself to understand Unicode and modern text encoding/processing, I was reminded that this is something that “every programmer should just know”, an idea that comes up every so often, usually in relation to a subject in which the speaker is already an expert. One of the most absurd examples I ever witnessed was a blog post along the lines of “What every working programmer ought to know about [some very specific niche of enterprise-level Java programming]“. I remember reading through the article and recognizing that I had almost no knowledge of the material. Disturbing, since I am demonstrably a “working programmer”.
For fun, I queried the googles on the matter of what ever programmer ought to know.
Specific Topics
Here is what every programmer should know about: Unicode, time, memory (simple), memory (extremely in-depth), regular expressions, search engine optimization, floating point, security, basic number theory, race conditions, managed C++, VIM commands, distributed systems, object-oriented design, latency numbers, rate monotonic algorithm, merging branches in Mercurial, classes of algorithms, and human names.Broader Topics
20 subjects every programmer should know, 97 things every programmer should know, 12 things every programmer should know, things every programmer should know (27 items), 10 papers every programmer should read at least twice, 10 things every programmer should know for their first job.Meanwhile, I remain fond of this xkcd comic whose mouseover text describes all that a person genuinely needs to know. Still, the new year is upon us, a time when people often make commitments to bettering themselves, and it couldn’t hurt (much) to at least skim some of the lists and find out what you never knew that you never knew.
What About Multimedia?
Reading the foregoing (or the titles of the foregoing pieces), I naturally wonder if I should write something about what every programmer should know about multimedia. I think it would look something like a multimedia programming FAQ. These are some items that I can think of:- YUV: The other colorspace (since most programmers are only familiar with RGB and have no idea what to make of the YUV that comes out of most video decoding APIs)
- Why you can’t easily seek randomly to any specific frame in a video file (keyframe/interframe discussion and their implications)
- Understand your platform before endeavoring to implement multimedia software (modern platforms, particularly mobile platforms, probably provide everything you need in the native APIs and there is likely little reason to compile libavcodec for the platform)
- Difference between containers and codecs (longstanding item, but I would argue it’s less relevant these days due to standardization on the MPEG — MP4/H.264/AAC — stack)
- What counts as a multimedia standard in this day and age (comparing the foregoing MPEG stack with the WebM/VP8/Vorbis stack)
- Trade-offs to consider when engineering a multimedia solution
- Optimization doesn’t always work the way you think it does (not everything touted as a massive speed-up in the world of computing — whether it be multithreaded CPUs, GPGPUs, new SIMD instruction sets — will necessarily be applicable to multimedia processing)
- A practical guide to legal issues would not be amiss
- ???
What other items count as “something multimedia-related that every programmer should know”?