Recherche avancée
Autres articles (67)
-
Le profil des utilisateurs
12 avril 2011, parChaque utilisateur dispose d’une page de profil lui permettant de modifier ses informations personnelle. Dans le menu de haut de page par défaut, un élément de menu est automatiquement créé à l’initialisation de MediaSPIP, visible uniquement si le visiteur est identifié sur le site.
L’utilisateur a accès à la modification de profil depuis sa page auteur, un lien dans la navigation "Modifier votre profil" est (...) -
Configurer la prise en compte des langues
15 novembre 2010, parAccéder à la configuration et ajouter des langues prises en compte
Afin de configurer la prise en compte de nouvelles langues, il est nécessaire de se rendre dans la partie "Administrer" du site.
De là, dans le menu de navigation, vous pouvez accéder à une partie "Gestion des langues" permettant d’activer la prise en compte de nouvelles langues.
Chaque nouvelle langue ajoutée reste désactivable tant qu’aucun objet n’est créé dans cette langue. Dans ce cas, elle devient grisée dans la configuration et (...) -
XMP PHP
13 mai 2011, parDixit Wikipedia, XMP signifie :
Extensible Metadata Platform ou XMP est un format de métadonnées basé sur XML utilisé dans les applications PDF, de photographie et de graphisme. Il a été lancé par Adobe Systems en avril 2001 en étant intégré à la version 5.0 d’Adobe Acrobat.
Étant basé sur XML, il gère un ensemble de tags dynamiques pour l’utilisation dans le cadre du Web sémantique.
XMP permet d’enregistrer sous forme d’un document XML des informations relatives à un fichier : titre, auteur, historique (...)
Sur d’autres sites (5681)
-
The first in-depth technical analysis of VP8

Back in my original post about Internet video, I made some initial comments on the hope that VP8 would solve the problems of web video by providing a supposed patent-free video format with significantly better compression than the current options of Theora and Dirac. Fortunately, it seems I was able to acquire access to the VP8 spec, software, and source a good few days before the official release and so was able to perform a detailed technical analysis in time for the official release.
The questions I will try to answer here are :
1. How good is VP8 ? Is the file format actually better than H.264 in terms of compression, and could a good VP8 encoder beat x264 ? On2 claimed 50% better than H.264, but On2 has always made absurd claims that they were never able to back up with results, so such a number is almost surely wrong. VP7, for example, was claimed to be 15% better than H.264 while being much faster, but was in reality neither faster nor higher quality.
2. How good is On2′s VP8 implementation ? Irrespective of how good the spec is, is the implementation good, or is this going to be just like VP3, where On2 releases an unusably bad implementation with the hope that the community will fix it for them ? Let’s hope not ; it took 6 years to fix Theora !
3. How likely is VP8 to actually be free of patents ? Even if VP8 is worse than H.264, being patent-free is still a useful attribute for obvious reasons. But as noted in my previous post, merely being published by Google doesn’t guarantee that it is. Microsoft did similar a few years ago with the release of VC-1, which was claimed to be patent-free — but within mere months after release, a whole bunch of companies claimed patents on it and soon enough a patent pool was formed.
We’ll start by going through the core features of VP8. We’ll primarily analyze them by comparing to existing video formats. Keep in mind that an encoder and a spec are two different things : it’s possible for good encoder to be written for a bad spec or vice versa ! Hence why a really good MPEG-1 encoder can beat a horrific H.264 encoder.
But first, a comment on the spec itself.
AAAAAAAGGGGGGGGGGGGGHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH !
The spec consists largely of C code copy-pasted from the VP8 source code — up to and including TODOs, “optimizations”, and even C-specific hacks, such as workarounds for the undefined behavior of signed right shift on negative numbers. In many places it is simply outright opaque. Copy-pasted C code is not a spec. I may have complained about the H.264 spec being overly verbose, but at least it’s precise. The VP8 spec, by comparison, is imprecise, unclear, and overly short, leaving many portions of the format very vaguely explained. Some parts even explicitly refuse to fully explain a particular feature, pointing to highly-optimized, nigh-impossible-to-understand reference code for an explanation. There’s no way in hell anyone could write a decoder solely with this spec alone.
Now that I’ve gotten that out of my system, let’s get back to VP8 itself. To begin with, to get a general sense for where all this fits in, basically all modern video formats work via some variation on the following chain of steps :
Encode : Predict -> Transform + Quant -> Entropy Code -> Loopfilter
Decode : Entropy Decode -> Predict -> Dequant + Inverse Transform -> LoopfilterIf you’re looking to just get to the results and skip the gritty technical details, make sure to check out the “overall verdict” section and the “visual results” section. Or at least skip to the “summary for the lazy”.
Prediction
Prediction is any step which attempts to guess the content of an area of the frame. This could include functions based on already-known pixels in the same frame (e.g. inpainting) or motion compensation from a previous frame. Prediction usually involves side data, such as a signal telling the decoder a motion vector to use for said motion compensation.
Intra Prediction
Intra prediction is used to guess the content of a block without referring to other frames. VP8′s intra prediction is basically ripped off wholesale from H.264 : the “subblock” prediction modes are almost exactly identical (they even have the same names !) to H.264′s i4x4 mode, and the whole block prediction mode is basically identical to i16x16. Chroma prediction modes are practically identical as well. i8x8, from H.264 High Profile, is not present. An additional difference is that the planar prediction mode has been replaced with TM_PRED, a very vaguely similar analogue. The specific prediction modes are internally slightly different, but have the same names as in H.264.
Honestly, I’m very disappointed here. While H.264′s intra prediction is good, it has certainly been improved on quite a bit over the past 7 years, and I thought that blatantly ripping it off was the domain of companies like Real (see RV40). I expected at least something slightly more creative out of On2. But more important than any of that : this is a patent time-bomb waiting to happen. H.264′s spatial intra prediction is covered in patents and I don’t think that On2 will be able to just get away with changing the rounding in the prediction modes. I’d like to see Google’s justification for this — they must have a good explanation for why they think there won’t be any patent issues.
Update : spatial intra prediction apparently dates back to Nokia’s MVC H.26L proposal, from around 2000. It’s possible that Google believes that this is sufficient prior art to invalidate existing patents — which is not at all unreasonable !
Verdict on Intra Prediction : Slightly modified ripoff of H.264. Somewhat worse than H.264 due to omission of i8x8.
Inter Prediction
Inter prediction is used to guess the content of a block by referring to past frames. There are two primary components to inter prediction : reference frames and motion vectors. The reference frame is a past frame from which to grab pixels from and the motion vectors index an offset into that frame. VP8 supports a total of 3 reference frames : the previous frame, the “alt ref” frame, and the “golden frame”. For motion vectors, VP8 supports variable-size partitions much like H.264. For subpixel precision, it supports quarter-pel motion vectors with a 6-tap interpolation filter. In short :
VP8 reference frames : up to 3
H.264 reference frames : up to 16
VP8 partition types : 16×16, 16×8, 8×16, 8×8, 4×4
H.264 partition types : 16×16, 16×8, 8×16, flexible subpartitions (each 8×8 can be 8×8, 8×4, 4×8, or 4×4).
VP8 chroma MV derivation : each 4×4 chroma block uses the average of colocated luma MVs (same as MPEG-4 ASP)
H.264 chroma MV derivation : chroma uses luma MVs directly
VP8 interpolation filter : qpel, 6-tap luma, mixed 4/6-tap chroma
H.264 interpolation filter : qpel, 6-tap luma (staged filter), bilinear chroma
H.264 has but VP8 doesn’t : B-frames, weighted predictionH.264 has a significantly better and more flexible referencing structure. Sub-8×8 partitions are mostly unnecessary, so VP8′s omission of the H.264-style subpartitions has little consequence. The chroma MV derivation is more accurate in H.264 but slightly slower ; in practice the difference is probably near-zero both speed and compression-wise, since sub-8×8 luma partitions are rarely used (and I would suspect the same carries over to VP8).
The VP8 interpolation filter is likely slightly better, but will definitely be slower to implement, both encoder and decoder-side. A staged filter allows the encoder to precalculate all possible halfpel positions and then quickly calculate qpel positions when necessary : an unstaged filter does not, making subpel motion estimation much slower. Not that unstaged filters are bad — staged filters have basically been abandoned for all of the H.265 proposals — it’s just an inherent disadvantage performance-wise. Additionally, having as high as 6 taps on chroma is, IMO, completely unnecessary and wasteful.
The lack of B-frames in VP8 is a killer. B-frames can give 10-20% (or more) compression benefit for minimal speed cost ; their omission in VP8 probably costs more compression than all other problems noted in this post combined. This was not unexpected, however ; On2 has never used B-frames in any of their video formats. They also likely present serious patent problems, which probably explains their omission. Lack of weighted prediction is also going to hurt a bit, especially in fades.
Update : Alt-ref frames can apparently be used to partially replicate the lack of B-frames. It’s not nearly as good, but it can get at least some of the benefit without actual B-frames.
Verdict on Inter Prediction : Similar partitioning structure to H.264. Much weaker referencing structure. More complex, slightly better interpolation filter. Mostly a wash — except for the lack of B-frames, which is seriously going to hurt compression.
Transform and Quantization
After prediction, the encoder takes the difference between the prediction and the actual source pixels (the residual), transforms it, and quantizes it. The transform step is designed to make the data more amenable to compression by decorrelating it. The quantization step is the actual information-losing step where compression occurs ; the output values of transform are rounded, mostly to zero, leaving only a few integer coefficients.
Transform
For transform, VP8 uses again a very H.264-reminiscent scheme. Each 16×16 macroblock is divided into 16 4×4 DCT blocks, each of which is transformed by a bit-exact DCT approximation. Then, the DC coefficients of each block are collected into another 4×4 group, which is then Hadamard-transformed. OK, so this isn’t reminiscent of H.264, this is H.264. There are, however, 3 differences between VP8′s scheme and H.264′s.
The first is that the 8×8 transform is omitted entirely (fitting with the omission of the i8x8 intra mode). The second is the specifics of the transform itself. H.264 uses an extremely simplified “DCT” which is so un-DCT-like that it often referred to as the HCT (H.264 Cosine Transform) instead. This simplified transform results in roughly 1% worse compression, but greatly simplifies the transform itself, which can be implemented entirely with adds, subtracts, and right shifts by 1. VC-1 uses a more accurate version that relies on a few small multiplies (numbers like 17, 22, 10, etc). VP8 uses an extremely, needlessly accurate version that uses very large multiplies (20091 and 35468). This in retrospect is not surpising, as it is very similar to what VP3 used.
The third difference is that the Hadamard hierarchical transform is applied for some inter blocks, not merely i16x16. In particular, it also runs for p16x16 blocks. While this is definitely a good idea, especially given the small transform size (and the need to decorrelate the DC value between the small transforms), I’m not quite sure I agree with the decision to limit it to p16x16 blocks ; it seems that perhaps with a small amount of modification this could also be useful for other motion partitions. Also, note that unlike H.264, the hierarchical transform is luma-only and not applied to chroma.
Overall, the transform scheme in VP8 is definitely weaker than in H.264. The lack of an 8×8 transform is going to have a significant impact on detail retention, especially at high resolutions. The transform is needlessly slower than necessary as well, though a shift-based transform might be out of the question due to patents. The one good new idea here is applying the hierarchical DC transform to inter blocks.
Verdict on Transform : Similar to H.264. Slower, slightly more accurate 4×4 transform. Improved DC transform for luma (but not on chroma). No 8×8 transform. Overall, worse.
Quantization
For quantization, the core process is basically the same among all MPEG-like video formats, and VP8 is no exception. The primary ways that video formats tend to differentiate themselves here is by varying quantization scaling factors. There are two ways in which this is primarily done : frame-based offsets that apply to all coefficients or just some portion of them, and macroblock-level offsets. VP8 primarily uses the former ; in a scheme much less flexible than H.264′s custom quantization matrices, it allows for adjusting the quantizer of luma DC, luma AC, chroma DC, and so forth, separately. The latter (macroblock-level quantizer choice) can, in theory, be done using its “segmentation map” features, albeit very hackily and not very efficiently.
The killer mistake that VP8 has made here is not making macroblock-level quantization a core feature of VP8. Algorithms that take advantage of macroblock-level quantization are known as “adaptive quantization” and are absolutely critical to competitive visual quality. My implementation of variance-based adaptive quantization (before, after) in x264 still stands to this day as the single largest visual quality gain in x264 history. Encoder comparisons have showed over and over that encoders without adaptive quantization simply cannot compete.
Thus, while adaptive quantization is possible in VP8, the only way to implement it is to define one segment map for every single quantizer that one wants and to code the segment map index for every macroblock. This is inefficient and cumbersome ; even the relatively suboptimal MPEG-style delta quantizer system would be a better option. Furthermore, only 4 segment maps are allowed, for a maximum of 4 quantizers per frame.
Verdict on Quantization : Lack of well-integrated adaptive quantization is going to be a killer when the time comes to implement psy optimizations. Overall, much worse.
Entropy Coding
Entropy coding is the process of taking all the information from all the other processes : DCT coefficients, prediction modes, motion vectors, and so forth — and compressing them losslessly into the final output file. VP8 uses an arithmetic coder somewhat similar to H.264′s, but with a few critical differences. First, it omits the range/probability table in favor of a multiplication. Second, it is entirely non-adaptive : unlike H.264′s, which adapts after every bit decoded, probability values are constant over the course of the frame. Accordingly, the encoder may periodically send updated probability values in frame headers for some syntax elements. Keyframes reset the probability values to the defaults.
This approach isn’t surprising ; VP5 and VP6 (and probably VP7) also used non-adaptive arithmetic coders. How much of a penalty this actually means compression-wise is unknown ; it’s not easy to measure given the design of either H.264 or VP8. More importantly, I question the reason for this : making it adaptive would add just one single table lookup to the arithmetic decoding function — hardly a very large performance impact.
Of course, the arithmetic coder is not the only part of entropy coding : an arithmetic coder merely turns 0s and 1s into an output bitstream. The process of creating those 0s and 1s and selecting the probabilities for the encoder to use is an equally interesting problem. Since this is a very complicated part of the video format, I’ll just comment on the parts that I found particularly notable.
Motion vector coding consists of two parts : prediction based on neighboring motion vectors and the actual compression of the resulting delta between that and the actual motion vector. The prediction scheme in VP8 is a bit odd — worse, the section of the spec covering this contains no English explanation, just confusingly-written C code. As far as I can tell, it chooses an arithmetic coding context based on the neighboring MVs, then decides which of the predicted motion vectors to use, or whether to code a delta instead.
The downside of this scheme is that, like in VP3/Theora (though not nearly as badly), it biases heavily towards the re-use of previous motion vectors. This is dangerous because, as the Theora devs have recently found (and fixed to some extent in Theora 1.2 aka Ptalabvorm), any situation in which the encoder picks a motion vector which isn’t the “real” motion vector in order to save bits can potentially have negative visual consequences. In terms of raw efficiency, I’m not sure whether VP8 or H.264′s prediction is better here.
The compression of the resulting delta is similar to H.264, except for the coding of very large deltas, which is slightly better (similar to FFV1′s Golomb-like arithmetic codes).
Intra prediction mode coding is done using arithmetic coding contexts based on the modes of the neighboring blocks. This is probably a good bit better than the hackneyed method that H.264 uses, which always struck me as being poorly designed.
Residual coding is even more difficult to understand than motion vector coding, as the only full reference is a bunch of highly optimized, highly obfuscated C code. Like H.264′s CAVLC, it bases contexts on the number of nonzero coefficients in the top and left blocks relative to the current block. In addition, it also considers the magnitude of those coefficients and, like H.264′s CABAC, updates as coefficients are decoded.
One more thing to note is the data partitioning scheme used by VP8. This scheme is much like VP3/Theora’s and involves putting each syntax element in its own component of the bitstream. The unfortunate problem with this is that it’s a nightmare for hardware implementations, greatly increasing memory bandwidth requirements. I have already received a complaint from a hardware developer about this specific feature with regard to VP8.
Verdict on Entropy Coding : I’m not quite sure here. It’s better in some ways, worse in some ways, and just plain weird in others. My hunch is that it’s probably a very slight win for H.264 ; non-adaptive arithmetic coding has to have some serious penalties. It may also be a hardware implementation problem.
Loop Filter
The loop filter is run after decoding or encoding a frame and serves to perform extra processing on a frame, usually to remove blockiness in DCT-based video formats. Unlike postprocessing, this is not only for visual reasons, but also to improve prediction for future frames. Thus, it has to be done identically in both the encoder and decoder. VP8′s loop filter is vaguely similar to H.264′s, but with a few differences. First, it has two modes (which can be chosen by the encoder) : a fast mode and a normal mode. The fast mode is somewhat simpler than H.264′s, while the normal mode is somewhat more complex. Secondly, when filtering between macroblocks, VP8′s filter has wider range than the in-macroblock filter — H.264 did this, but only for intra edges.
Third, VP8′s filter omits most of the adaptive strength mechanics inherent in H.264′s filter. Its only adaptation is that it skips filtering on p16x16 blocks with no coefficients. This may be responsible for the high blurriness of VP8′s loop filter : it will run over and over and over again on all parts of a macroblock even if they are unchanged between frames (as long as some other part of the macroblock is changed). H.264′s, by comparison, is strength-adaptive based on whether DCT coefficients exist on either side of a given edge and based on the motion vector delta and reference frame delta across said edge. Of course, skipping this strength calculation saves some decoding time as well.
Update :
05:28 < derf> Gumboot : You’ll be disappointed to know they got the loop filter ordering wrong again.
05:29 < derf> Dark_Shikari : They ordered it such that you have to process each macroblock in full before processing the next one.Verdict on Loop Filter : Definitely worse compression-wise than H.264′s due to the lack of adaptive strength. Especially with the “fast” mode, might be significantly faster. I worry about it being too blurry.
Overall verdict on the VP8 video format
Overall, VP8 appears to be significantly weaker than H.264 compression-wise. The primary weaknesses mentioned above are the lack of proper adaptive quantization, lack of B-frames, lack of an 8×8 transform, and non-adaptive loop filter. With this in mind, I expect VP8 to be more comparable to VC-1 or H.264 Baseline Profile than with H.264. Of course, this is still significantly better than Theora, and in my tests it beats Dirac quite handily as well.
Supposedly Google is open to improving the bitstream format — but this seems to conflict with the fact that they got so many different companies to announce VP8 support. The more software that supports a file format, the harder it is to change said format, so I’m dubious of any claim that we will be able to spend the next 6-12 months revising VP8. In short, it seems to have been released too early : it would have been better off to have an initial period during which revisions could be submitted and then a big announcement later when it’s completed.
Update : it seems that Google is not open to changing the spec : it is apparently “final”, complete with all its flaws.
In terms of decoding speed I’m not quite sure ; the current implementation appears to be about 16% slower than ffmpeg’s H.264 decoder (and thus probably about 25-35% slower than state-of-the-art decoders like CoreAVC). Of course, this doesn’t necessarily say too much about what a fully optimized implementation will reach, but the current one seems to be reasonably well-optimized and has SIMD assembly code for almost all major DSP functions, so I doubt it will get that much faster.
I would expect, with equally optimized implementations, VP8 and H.264 to be relatively comparable in terms of decoding speed. This, of course, is not really a plus for VP8 : H.264 has a great deal of hardware support, while VP8 largely has to rely on software decoders, so being “just as fast” is in many ways not good enough. By comparison, Theora decodes almost 35% faster than H.264 using ffmpeg’s decoder.
Finally, the problem of patents appears to be rearing its ugly head again. VP8 is simply way too similar to H.264 : a pithy, if slightly inaccurate, description of VP8 would be “H.264 Baseline Profile with a better entropy coder”. Even VC-1 differed more from H.264 than VP8 does, and even VC-1 didn’t manage to escape the clutches of software patents. It’s quite possible that VP8 has no patent issues, but until we get some hard evidence that VP8 is safe, I would be cautious. Since Google is not indemnifying users of VP8 from patent lawsuits, this is even more of a potential problem. Most importantly, Google has not released any justifications for why the various parts of VP8 do not violate patents, as Sun did with their OMS standard : such information would certainly cut down on speculation and make it more clear what their position actually is.
But if luck is on Google’s side and VP8 does pass through the patent gauntlet unscathed, it will undoubtedly be a major upgrade as compared to Theora.
Addendum A : On2′s VP8 Encoder and Decoder
This post is primarily aimed at discussing issues relating to the VP8 video format. But from a practical perspective, while software can be rewritten and improved, to someone looking to use VP8 in the near future, the quality (both code-wise, compression-wise, and speed-wise) of the official VP8 encoder and decoder is more important than anything I’ve said above. Thus, after reading through most of the code, here’s my thoughts on the software.
Initially I was intending to go easy on On2 here ; I assumed that this encoder was in fact new for VP8 and thus they wouldn’t necessarily have time to make the code high-quality and improve its algorithms. However, as I read through the encoder, it became clear that this was not at all true ; there were comments describing bugfixes dating as far back as early 2004. That’s right : this software is even older than x264 ! I’m guessing that the current VP8 software simply evolved from the original VP7 software. Anyways, this means that I’m not going to go easy on On2 ; they’ve had (at least) 6 years to work on VP8, and a much larger dev team than x264′s to boot.
Before I tear the encoder apart, keep in mind that it isn’t bad. In fact, compression-wise, I don’t think they’re going to be able to get it that much better using standard methods. I would guess that the encoder, on slowest settings, is within 5-10% of the maximum PSNR that they’ll ever get out of it. There’s definitely a whole lot more to be had using unusual algorithms like MB-tree, not to mention the complete lack of psy optimizations — but at what it tries to do, it does pretty decently. This is in contrast to the VP3 encoder, which was a pile of garbage (just ask any Theora dev).
Before I go into specific components, a general note on code quality. The code quality is much better than VP3, though there’s still tons of typos in the comments. They also appear to be using comments as a form of version control system, which is a bit bizarre. The assembly code is much worse, with staggering levels of copy-paste coding, some completely useless instructions that do nothing at all, unaligned loads/stores to what-should-be aligned data structures, and a few functions that are simply written in unfathomably roundabout (and slower) ways. While the C code isn’t half bad, the assembly is clearly written by retarded monkeys. But I’m being unfair : this is way better than with VP3.
Motion estimation : Diamond, hex, and exhaustive (full) searches available. All are pretty naively implemented : hexagon, for example, performs a staggering amount of redundant work (almost half of the locations it searches are repeated !). Full is even worse in terms of inefficiency, but it’s useless for all but placebo-level speeds, so I’m not really going to complain about that.
Subpixel motion estimation : Straightforward iterative diamond and square searches. Nothing particularly interesting here.
Quantization : Primary quantization has two modes : a fast mode and a slightly slower mode. The former is just straightforward deadzone quant, while the latter has a bias based on zero-run length (not quite sure how much this helps, but I like the idea). After this they have “coefficient optimization” with two modes. One mode simply tries moving each nonzero coefficient towards zero ; the slow mode tries all 2^16 possible DCT coefficient rounding permutations. Whoever wrote this needs to learn what trellis quantization (the dynamic programming solution to the problem) is and stop using exponential-time algorithms in encoders.
Ratecontrol (frame type handling) : Relies on “boosting” the quality of golden frames and “alt-ref” frames — a concept I find extraordinarily dubious because it means that the video will periodically “jump” to a higher quality level, which looks utterly terrible in practice. You can see the effect in this graph of PSNR ; every dozen frames or so, the quality “jumps”. This cannot possibly look good in motion.
Ratecontrol (overall) : Relies on a purely reactive ratecontrol algorithm, which probably will not do very well in difficult situations such as hard-CBR and tight buffer constraints. Furthermore, it does no adaptation of the quantizer within the frame (e.g. in the case that the frame overshot the size limitations ratecontrol put on it). Instead, it relies on re-encoding the frame repeatedly to reach the target size — which in practice is simply not a usable option for two reasons. In low-latency situations where one can’t have a large delay, re-encoding repeatedly may send the encoder way behind time-wise. In any other situation, one can afford to use frame-based threading, a much faster algorithm for multithreaded encoding than the typical slice-based threading — which makes re-encoding impossible.
Loop filter : The encoder attempts to optimize the loop filter parameters for maximum PSNR. I’m not quite sure how good an idea this is ; every example I’ve seen of this with H.264 ends up creating very bad (often blurry) visual results.
Overall performance : Even on the absolute fastest settings with multithreading, their encoder is slow. On my 1.6Ghz Core i7 it gets barely 26fps encoding 1080p ; not even enough to reliably do real-time compression. x264, by comparison, gets 101fps at its fastest preset “ultrafast”. Now, sure, I don’t expect On2′s encoder to be anywhere near as fast as x264, but being unable to stream HD video on a modern quad-core system is simply not reasonable in 2010. Additionally, the speed options are extraordinarily confusing and counterintuitive and don’t always seem to work properly ; for example, fast encoding mode (–rt) seems to be ignored completely in 2-pass.
Overall compression : As said before, compression-wise the encoder does a pretty good job with the spec that it’s given. The slower algorithms in the encoder are clearly horrifically unoptimized (see the comments on motion search and quantization in particular), but they still work.
Decoder : Seems to be straightforward enough. Nothing jumped out at me as particularly bad, slow, or otherwise, besides the code quality issues mentioned above.
Practical problems : The encoder and decoder share a staggering amount of code. This means that any bug in the common code will affect both, and thus won’t be spotted because it will affect them both in a matching fashion. This is the inherent problem with any file format that doesn’t have independent implementations and is defined by a piece of software instead of a spec : there are always bugs. RV40 had a hilarious example of this, where a typo of “22″ instead of “33″ resulted in quarter-pixel motion compensation being broken. Accordingly, I am very dubious of any file format defined by software instead of a specification. Google should wait until independent implementations have been created before setting the spec in stone.
Update : it seems that what I forsaw is already coming true :
<derf> gmaxwell : It survives it with a patch that causes artifacts because their encoder doesn’t clamp MVs properly.
<gmaxwell> ::cries: :
<derf> So they reverted my decoder patch, instead of fixing the encoder.
<gmaxwell> “but we have many files encoded with this !”
<gmaxwell> so great.. single implementation and it depends on its own bugs.
This is just like Internet Explorer 6 all over again — bugs in the software become part of the “spec” !
Hard PSNR numbers :
(Source/target bitrate are the same as in my upcoming comparison.)
x264, slowest mode, High Profile : 29.76103db ( 28% better than VP8)
VP8, slowest mode : 28.37708db ( 8.5% better than x264 baseline)
x264, slowest mode, Baseline Profile : 27.95594dbNote that these numbers are a “best-case” situation : we’re testing all three optimized for PSNR, which is what the current VP8 encoder specializes in as well. This is not too different from my expectations above as estimated from the spec itself ; it’s relatively close to x264′s Baseline Profile.
Keep in mind that this is not representative of what you can get out of VP8 now, but rather what could be gotten out of VP8. PSNR is meaningless for real-world encoding — what matters is visual quality — so hopefully if problems like the adaptive quantization issue mentioned previously can be overcome, the VP8 encoder could be improved to have x264-level psy optimizations. However, as things stand…
Visual results : Unfortunately, since the current VP8 encoder optimizes entirely for PSNR, the visual results are less than impressive. Here’s a sampling of how it compares with some other encoders. Source and bitrate are the same as above ; all encoders are optimized for optimal visual quality wherever possible. And apparently given some of the responses to this part, many people cannot actually read ; the bitrate is (as close as possible to) the same on all of these files.
Update : I got completely slashdotted and my few hundred gigs of bandwidth ran out in mere hours. The images below have been rehosted, so if you’ve pasted the link somewhere else, check below for the new one.
VP8 (On2 VP8 rc8) (source) (Note : I recently realized that the official encoder doesn’t output MKV, so despite the name, this file is actually a VP8 bitstream wrapped in IVF, as generated by ivfenc. Decode it with ivfdec.)
H.264 (Recent x264) (source)
H.264 Baseline Profile (Recent x264) (source)
Theora (Recent ptalabvorm nightly) (source)
Dirac (Schroedinger 1.0.9) (source)
VC-1 (Microsoft VC-1 SDK) (source)
MPEG-4 ASP (Xvid 1.2.2) (source)The quality generated by On2′s VP8 encoder will probably not improve significantly without serious psy optimizations.
One further note about the encoder : currently it will drop frames by default, which is incredibly aggravating and may cause serious problems. I strongly suggest anyone using it to turn the frame-dropping feature off in the options.
Addendum B : Google’s choice of container and audio format for HTML5
Google has chosen Matroska for their container format. This isn’t particularly surprising : Matroska is one of the most widely used “modern” container formats and is in many ways best-suited to the task. MP4 (aka ISOmedia) is probably a better-designed format, but is not very flexible ; while in theory it can stick anything in a private stream, a standardization process is technically necessary to “officially” support any new video or audio formats. Patents are probably a non-issue ; the MP4 patent pool was recently disbanded, largely because nobody used any of the features that were patented.
Another advantage of Matroska is that it can be used for streaming video : while it isn’t typically, the spec allows it. Note that I do not mean progressive download (a’la Youtube), but rather actual streaming, where the encoder is working in real-time. The only way to do this with MP4 is by sending “segments” of video, a very hacky approach in which one is effectively sending a bunch of small MP4 files in sequence. This approach is used by Microsoft’s Silverlight “Smooth Streaming”. Not only is this an ugly hack, but it’s unsuitable for low-latency video. This kind of hack is unnecessary for Matroska. One possible problem is that since almost nobody currently uses Matroska for live streaming purposes, very few existing Matroska implementations support what is necessary to play streamed Matroska files.
I’m not quite sure why Google chose to rebrand Matroska ; “WebM” is a silly name and Matroska is already pretty well-recognized as a brand.
The choice of Vorbis for audio is practically a no-brainer. Even ignoring the issue of patents, libvorbis is still the best general-purpose open source audio encoder. While AAC is generally better at very low bitrates, there aren’t any good open source AAC encoders : faac is worse than LAME and ffmpeg’s AAC encoder is even worse. Furthermore, faac is not free software ; it contains code from the non-free reference encoder. Combined with the patent issue, nobody expected Google to pick anything else.
Addendum C : Summary for the lazy
VP8, as a spec, should be a bit better than H.264 Baseline Profile and VC-1. It’s not even close to competitive with H.264 Main or High Profile. If Google is willing to revise the spec, this can probably be improved.
VP8, as an encoder, is somewhere between Xvid and Microsoft’s VC-1 in terms of visual quality. This can definitely be improved a lot.
VP8, as a decoder, decodes even slower than ffmpeg’s H.264. This probably can’t be improved that much ; VP8 as a whole is similar in complexity to H.264.
With regard to patents, VP8 copies too much from H.264 for comfort, no matter whose word is behind the claim of being patent-free. This doesn’t mean that it’s sure to be covered by patents, but until Google can give us evidence as to why it isn’t, I would be cautious.
VP8 is definitely better compression-wise than Theora and Dirac, so if its claim to being patent-free does stand up, it’s a big upgrade with regard to patent-free video formats.
VP8 is not ready for prime-time ; the spec is a pile of copy-pasted C code and the encoder’s interface is lacking in features and buggy. They aren’t even ready to finalize the bitstream format, let alone switch the world over to VP8.
With the lack of a real spec, the VP8 software basically is the spec–and with the spec being “final”, any bugs are now set in stone. Such bugs have already been found and Google has rejected fixes.
Google made the right decision to pick Matroska and Vorbis for its HTML5 video proposal.
29.76103
-
Open Media Developers Track at OVC 2011
11 octobre 2011, par silviaThe Open Video Conference that took place on 10-12 September was so overwhelming, I’ve still not been able to catch my breath ! It was a dense three days for me, even though I only focused on the technology sessions of the conference and utterly missed out on all the policy and content discussions.
Roughly 60 people participated in the Open Media Software (OMS) developers track. This was an amazing group of people capable and willing to shape the future of video technology on the Web :
- HTML5 video developers from Apple, Google, Opera, and Mozilla (though we missed the NZ folks),
- codec developers from WebM, Xiph, and MPEG,
- Web video developers from YouTube, JWPlayer, Kaltura, VideoJS, PopcornJS, etc.,
- content publishers from Wikipedia, Internet Archive, YouTube, Netflix, etc.,
- open source tool developers from FFmpeg, gstreamer, flumotion, VideoLAN, PiTiVi, etc,
- and many more.
To provide a summary of all the discussions would be impossible, so I just want to share the key take-aways that I had from the main sessions.
WebRTC : Realtime Communications and HTML5
Tim Terriberry (Mozilla), Serge Lachapelle (Google) and Ethan Hugg (CISCO) moderated this session together (slides). There are activities both at the W3C and at IETF – the ones at IETF are supposed to focus on protocols, while the W3C ones on HTML5 extensions.
The current proposal of a PeerConnection API has been implemented in WebKit/Chrome as open source. It is expected that Firefox will have an add-on by Q1 next year. It enables video conferencing, including media capture, media encoding, signal processing (echo cancellation etc), secure transmission, and a data stream exchange.
Current discussions are around the signalling protocol and whether SIP needs to be required by the standard. Further, the codec question is under discussion with a question whether to mandate VP8 and Opus, since transcoding gateways are not desirable. Another question is how to measure the quality of the connection and how to report errors so as to allow adaptation.
What always amazes me around RTC is the sheer number of specialised protocols that seem to be required to implement this. WebRTC does not disappoint : in fact, the question was asked whether there could be a lighter alternative than to re-use dozens of years of protocol development – is it over-engineered ? Can desktop players connect to a WebRTC session ?
We are already in a second or third revision of this part of the HTML5 specification and yet it seems the requirements are still being collected. I’m quietly confident that everything is done to make the lives of the Web developer easier, but it sure looks like a huge task.
The Missing Link : Flash to HTML5
Zohar Babin (Kaltura) and myself moderated this session and I must admit that this session was the biggest eye-opener for me amongst all the sessions. There was a large number of Flash developers present in the room and that was great, because sometimes we just don’t listen enough to lessons learnt in the past.
This session gave me one of those aha-moments : it the form of the Flash appendBytes() API function.
The appendBytes() function allows a Flash developer to take a byteArray out of a connected video resource and do something with it – such as feed it to a video for display. When I heard that Web developers want that functionality for JavaScript and the video element, too, I instinctively rejected the idea wondering why on earth would a Web developer want to touch encoded video bytes – why not leave that to the browser.
But as it turns out, this is actually a really powerful enabler of functionality. For example, you can use it to :
- display mid-roll video ads as part of the same video element,
- sequence playlists of videos into the same video element,
- implement DVR functionality (high-speed seeking),
- do mash-ups,
- do video editing,
- adaptive streaming.
This totally blew my mind and I am now completely supportive of having such a function in HTML5. Together with media fragment URIs you could even leave all the header download management for resources to the Web browser and just request time ranges from a video through an appendBytes() function. This would be easier on the Web developer than having to deal with byte ranges and making sure that appropriate decoding pipelines are set up.
Standards for Video Accessibility
Philip Jagenstedt (Opera) and myself moderated this session. We focused on the HTML5 track element and the WebVTT file format. Many issues were identified that will still require work.
One particular topic was to find a standard means of rendering the UI for caption, subtitle, und description selection. For example, what icons should be used to indicate that subtitles or captions are available. While this is not part of the HTML5 specification, it’s still important to get this right across browsers since otherwise users will get confused with diverging interfaces.
Chaptering was discussed and a particular need to allow URLs to directly point at chapters was expressed. I suggested the use of named Media Fragment URLs.
The use of WebVTT for descriptions for the blind was also discussed. A suggestion was made to use the voice tag <v> to allow for “styling” (i.e. selection) of the screen reader voice.
Finally, multitrack audio or video resources were also discussed and the @mediagroup attribute was explained. A question about how to identify the language used in different alternative dubs was asked. This is an issue because @srclang is not on audio or video, only on text, so it’s a missing feature for the multitrack API.
Beyond this session, there was also a breakout session on WebVTT and the track element. As a consequence, a number of bugs were registered in the W3C bug tracker.
WebM : Testing, Metrics and New features
This session was moderated by John Luther and John Koleszar, both of the WebM Project. They started off with a presentation on current work on WebM, which includes quality testing and improvements, and encoder speed improvement. Then they moved on to questions about how to involve the community more.
The community criticised that communication of what is happening around WebM is very scarce. More sharing of information was requested, including a move to using open Google+ hangouts instead of Google internal video conferences. More use of the public bug tracker can also help include the community better.
Another pain point of the community was that code is introduced and removed without much feedback. It was requested to introduce a peer review process. Also it was requested that example code snippets are published when new features are announced so others can replicate the claims.
This all indicates to me that the WebM project is increasingly more open, but that there is still a lot to learn.
Standards for HTTP Adaptive Streaming
This session was moderated by Frank Galligan and Aaron Colwell (Google), and Mark Watson (Netflix).
Mark started off by giving us an introduction to MPEG DASH, the MPEG file format for HTTP adaptive streaming. MPEG has just finalized the format and he was able to show us some examples. DASH is XML-based and thus rather verbose. It is covering all eventualities of what parameters could be switched during transmissions, which makes it very broad. These include trick modes e.g. for fast forwarding, 3D, multi-view and multitrack content.
MPEG have defined profiles – one for live streaming which requires chunking of the files on the server, and one for on-demand which requires keyframe alignment of the files. There are clear specifications for how to do these with MPEG. Such profiles would need to be created for WebM and Ogg Theora, too, to make DASH universally applicable.
Further, the Web case needs a more restrictive adaptation approach, since the video element’s API is already accounting for some of the features that DASH provides for desktop applications. So, a Web-specific profile of DASH would be required.
Then Aaron introduced us to the MediaSource API and in particular the webkitSourceAppend() extension that he has been experimenting with. It is essentially an implementation of the appendBytes() function of Flash, which the Web developers had been asking for just a few sessions earlier. This was likely the biggest announcement of OVC, alas a quiet and technically-focused one.
Aaron explained that he had been trying to find a way to implement HTTP adaptive streaming into WebKit in a way in which it could be standardised. While doing so, he also came across other requirements around such chunked video handling, in particular around dynamic ad insertion, live streaming, DVR functionality (fast forward), constraint video editing, and mashups. While trying to sort out all these requirements, it became clear that it would be very difficult to implement strategies for stream switching, buffering and delivery of video chunks into the browser when so many different and likely contradictory requirements exist. Also, once an approach is implemented and specified for the browser, it becomes very difficult to innovate on it.
Instead, the easiest way to solve it right now and learn about what would be necessary to implement into the browser would be to actually allow Web developers to queue up a chunk of encoded video into a video element for decoding and display. Thus, the webkitSourceAppend() function was born (specification).
The proposed extension to the HTMLMediaElement is as follows :
partial interface HTMLMediaElement // URL passed to src attribute to enable the media source logic. readonly attribute [URL] DOMString webkitMediaSourceURL ;
bool webkitSourceAppend(in Uint8Array data) ;
// end of stream status codes.
const unsigned short EOS_NO_ERROR = 0 ;
const unsigned short EOS_NETWORK_ERR = 1 ;
const unsigned short EOS_DECODE_ERR = 2 ;void webkitSourceEndOfStream(in unsigned short status) ;
// states
const unsigned short SOURCE_CLOSED = 0 ;
const unsigned short SOURCE_OPEN = 1 ;
const unsigned short SOURCE_ENDED = 2 ;readonly attribute unsigned short webkitSourceState ;
;The code is already checked into WebKit, but commented out behind a command-line compiler flag.
Frank then stepped forward to show how webkitSourceAppend() can be used to implement HTTP adaptive streaming. His example uses WebM – there are no examples with MPEG or Ogg yet.
The chunks that Frank’s demo used were 150 video frames long (6.25s) and 5s long audio. Stream switching only switched video, since audio data is much lower bandwidth and more important to retain at high quality. Switching was done on multiplexed files.
Every chunk requires an XHR range request – this could be optimised if the connections were kept open per adaptation. Seeking works, too, but since decoding requires download of a whole chunk, seeking latency is determined by the time it takes to download and decode that chunk.
Similar to DASH, when using this approach for live streaming, the server has to produce one file per chunk, since byte range requests are not possible on a continuously growing file.
Frank did not use DASH as the manifest format for his HTTP adaptive streaming demo, but instead used a hacked-up custom XML format. It would be possible to use JSON or any other format, too.
After this session, I was actually completely blown away by the possibilities that such a simple API extension allows. If I wasn’t sold on the idea of a appendBytes() function in the earlier session, this one completely changed my mind. While I still believe we need to standardise a HTTP adaptive streaming file format that all browsers will support for all codecs, and I still believe that a native implementation for support of such a file format is necessary, I also believe that this approach of webkitSourceAppend() is what HTML needs – and maybe it needs it faster than native HTTP adaptive streaming support.
Standards for Browser Video Playback Metrics
This session was moderated by Zachary Ozer and Pablo Schklowsky (JWPlayer). Their motivation for the topic was, in fact, also HTTP adaptive streaming. Once you leave the decisions about when to do stream switching to JavaScript (through a function such a wekitSourceAppend()), you have to expose stream metrics to the JS developer so they can make informed decisions. The other use cases is, of course, monitoring of the quality of video delivery for reporting to the provider, who may then decide to change their delivery environment.
The discussion found that we really care about metrics on three different levels :
- measuring the network performance (bandwidth)
- measuring the decoding pipeline performance
- measuring the display quality
In the end, it seemed that work previously done by Steve Lacey on a proposal for video metrics was generally acceptable, except for the playbackJitter metric, which may be too aggregate to mean much.
Device Inputs / A/V in the Browser
I didn’t actually attend this session held by Anant Narayanan (Mozilla), but from what I heard, the discussion focused on how to manage permission of access to video camera, microphone and screen, e.g. when multiple applications (tabs) want access or when the same site wants access in a different session. This may apply to real-time communication with screen sharing, but also to photo sharing, video upload, or canvas access to devices e.g. for time lapse photography.
Open Video Editors
This was another session that I wasn’t able to attend, but I believe the creation of good open source video editing software and similar video creation software is really crucial to giving video a broader user appeal.
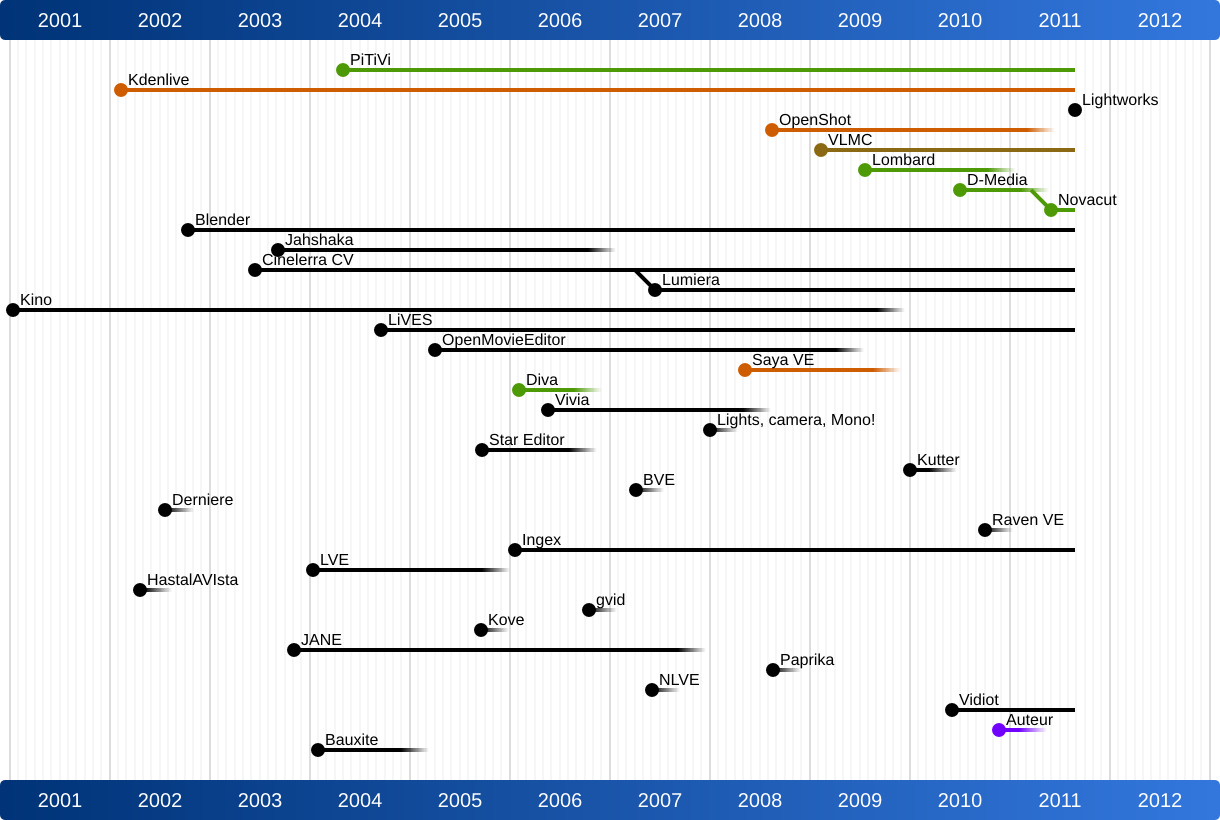
Jeff Fortin (PiTiVi) moderated this session and I was fascinated to later see his analysis of the lifecycle of open source video editors. It is shocking to see how many people/projects have tried to create an open source video editor and how many have stopped their project. It is likely that the creation of a video editor is such a complex challenge that it requires a larger and more committed open source project – single people will just run out of steam too quickly. This may be comparable to the creation of a Web browser (see the size of the Mozilla project) or a text processing system (see the size of the OpenOffice project).
Jeff also mentioned the need to create open video editor standards around playlist file formats etc. Possibly the Open Video Alliance could help. In any case, something has to be done in this space – maybe this would be a good topic to focus next year’s OVC on ?
Monday’s Breakout Groups
The conference ended officially on Sunday night, but we had a third day of discussions / hackday at the wonderful New York Lawschool venue. We had collected issues of interest during the two previous days and organised the breakout groups on the morning (Schedule).
In the Content Protection/DRM session, Mark Watson from Netflix explained how their API works and that they believe that all we need in browsers is a secure way to exchange keys and an indicator of protection scheme is used – the actual protection scheme would not be implemented by the browser, but be provided by the underlying system (media framework/operating system). I think that until somebody actually implements something in a browser fork and shows how this can be done, we won’t have much progress. In my understanding, we may also need to disable part of the video API for encrypted content, because otherwise you can always e.g. grab frames from the video element into canvas and save them from there.
In the Playlists and Gapless Playback session, there was massive brainstorming about what new cool things can be done with the video element in browsers if playback between snippets can be made seamless. Further discussions were about a standard playlist file formats (such as XSPF, MRSS or M3U), media fragment URIs in playlists for mashups, and the need to expose track metadata for HTML5 media elements.
What more can I say ? It was an amazing three days and the complexity of problems that we’re dealing with is a tribute to how far HTML5 and open video has already come and exciting news for the kind of applications that will be possible (both professional and community) once we’ve solved the problems of today. It will be exciting to see what progress we will have made by next year’s conference.
Thanks go to Google for sponsoring my trip to OVC.
UPDATE : We actually have a mailing list for open media developers who are interested in these and similar topics – do join at http://lists.annodex.net/cgi-bin/mailman/listinfo/foms.
-
Make better marketing decisions with attribution modeling
Do you suspect some traffic sources are not getting the rewards they deserve ? Do you want to know how much credit each of your marketing channel actually gets ?
When you look at which referrers contribute the most to your goal conversions or purchases, Piwik shows you only the referrer of the last visit. However, in reality, a visitor often visits a website multiple times from different referrers before they convert a goal. Giving all credit to the referrer of the last visit ignores all other referrers that contributed to a conversion as well.
You can now push your marketing analysis to the next level with attribution modeling and finally discover the true value of all your marketing channels. As a result, you will be able to shift your marketing efforts and spending accordingly to maximize your success and stop wasting resources. In marketing, studying this data is called attribution modeling.
Get the true value of your referrers
Attribution is a premium feature that you can easily purchase from the Piwik marketplace.
Once installed, you will be able to :
- identify valuable referrers that you did not see before
- invest in potential new partners
- attribute a new level of conversion
- make this work very easily by filling just a couple of form information
Identify valuable referrers that you did not see before
You probably have hundreds or even thousands of different sources listed within the referrer reports. We also guess that you have the feeling that it is always the same referrers which are credited of conversions.
Guess what, those data are probably biased or at least are not telling you the whole story.
Why ? Because by default, Piwik only attributes all credit to the last referrer.
It is likely that many non credited sources played a role in the conversion process as well as people often visit your website several times before converting and they may come from different referrers.
This is exactly where attribution modeling comes into play. With attribution modeling, you can decide which touchpoint you want to study. For example, you can choose to give credit to all the referrers a single visitor came from each time the user visits your website, and not only look at the last one. Without this feature, chances are, that you have spent too much money and / or efforts on the wrong referrer channels in the past because many referrers that contributed to conversions were ignored. Based on the insights you get by applying different attribution models, you can make better decisions on where to shift your marketing spending and efforts.
Invest in potential new partners
Once you apply different attribution models, you will find out that you need to consider a new list of referrers which you before either over- or under-estimated in terms of how much they contributed to your conversions. You probably did not identify those sources before because Piwik shows only the last referrer before a conversion. But you can now also look at what these newly discovered referrers are saying about your company, looking for any advertising programs they may offer, getting in contact with the owner of the website, and more.
Apply up to 6 different attribution models
By default, Piwik is attributing the conversion to the last referrer only. With attribution modeling you can analyze 6 different models :
- Last Interaction : the conversion is attributed to the last referrer, even if it is a direct access.
- Last Non-Direct : the conversion is attributed to the last referrer, but not in the case of a direct access.
- First Interaction : the conversion is attributed to the first referrer which brought you the visit.
- Linear : whatever the number of referrers which brought you the conversion, they will all get the same value.
- Position Based : first and last referrer will be attributed 40% each the conversion value, the remaining 60% is divided between the rest of the referrers.
- Time Decay : this attribution model means that the closer to the date of the conversion is, the more your last referrers will get credit.
Those attribution models will enable you to analyze all your referrers deeply and increase your conversions.
Let’s look at an example where we are comparing two models : “last interaction” and “first interaction”. Our goal is to identify whether some referrers that we are currently considering as less important, are finally playing a serious role in the total amount of conversions :

Comparing Last Interaction model to First Interaction model
Here it is interesting to observe that the website www.hongkiat.com is bringing almost 90% conversion more with the first interaction model rather than the last one.
As a result we can look at this website and take the following actions :
- have a look at the message on this website
- look at opportunities to change the message
- look at opportunities to display extra marketing messages
- get in contact with the owner to identify any other communication opportunities
The Multi Channel Attribution report
Attribution modeling in Piwik does not require you to add any tracking code. The only thing you need is to install the plugin and let the magic happen.
Simple as pie is the word you should keep in mind for this feature. Once installed, you will find the report within the goal section, just above the goals you created :
The Multi Attribution menu
There you can select the attribution model you would like to apply or compare.
Attribution modeling is not just about playing with a new report. It is above all an opportunity to increase the number of conversions by identifying referrers that you may have not recognized as valuable in the past. To grow your business, it is crucial to identify the most (and least) successful channels correctly so you can spend your time and money wisely.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}