Recherche avancée
Médias (1)
-

GetID3 - Bloc informations de fichiers
9 avril 2013, par
Mis à jour : Mai 2013
Langue : français
Type : Image
Autres articles (66)
-
Participer à sa traduction
10 avril 2011Vous pouvez nous aider à améliorer les locutions utilisées dans le logiciel ou à traduire celui-ci dans n’importe qu’elle nouvelle langue permettant sa diffusion à de nouvelles communautés linguistiques.
Pour ce faire, on utilise l’interface de traduction de SPIP où l’ensemble des modules de langue de MediaSPIP sont à disposition. ll vous suffit de vous inscrire sur la liste de discussion des traducteurs pour demander plus d’informations.
Actuellement MediaSPIP n’est disponible qu’en français et (...) -
D’autres logiciels intéressants
12 avril 2011, parOn ne revendique pas d’être les seuls à faire ce que l’on fait ... et on ne revendique surtout pas d’être les meilleurs non plus ... Ce que l’on fait, on essaie juste de le faire bien, et de mieux en mieux...
La liste suivante correspond à des logiciels qui tendent peu ou prou à faire comme MediaSPIP ou que MediaSPIP tente peu ou prou à faire pareil, peu importe ...
On ne les connais pas, on ne les a pas essayé, mais vous pouvez peut être y jeter un coup d’oeil.
Videopress
Site Internet : (...) -
MediaSPIP 0.1 Beta version
25 avril 2011, parMediaSPIP 0.1 beta is the first version of MediaSPIP proclaimed as "usable".
The zip file provided here only contains the sources of MediaSPIP in its standalone version.
To get a working installation, you must manually install all-software dependencies on the server.
If you want to use this archive for an installation in "farm mode", you will also need to proceed to other manual (...)
Sur d’autres sites (9343)
-
WebVTT as a W3C Recommendation
1er janvier 2014, par silviaThree weeks ago I attended TPAC, the annual meeting of W3C Working Groups. One of the meetings was of the Timed Text Working Group (TT-WG), that has been specifying TTML, the Timed Text Markup Language. It is now proposed that WebVTT be also standardised through the same Working Group.
How did that happen, you may ask, in particular since WebVTT and TTML have in the past been portrayed as rival caption formats ? How will the WebVTT spec that is currently under development in the Text Track Community Group (TT-CG) move through a Working Group process ?
I’ll explain first why there is a need for WebVTT to become a W3C Recommendation, and then how this is proposed to be part of the Timed Text Working Group deliverables, and finally how I can see this working between the TT-CG and the TT-WG.
Advantages of a W3C Recommendation
TTML is a XML-based markup format for captions developed during the time that XML was all the hotness. It has become a W3C standard (a so-called “Recommendation”) despite not having been implemented in any browsers (if you ask me : that’s actually a flaw of the W3C standardisation process : it requires only two interoperable implementations of any kind – and that could be anyone’s JavaScript library or Flash demonstrator – it doesn’t actually require browser implementations. But I digress…). To be fair, a subpart of TTML is by now implemented in Internet Explorer, but all the other major browsers have thus far rejected proposals of implementation.
Because of its Recommendation status, TTML has become the basis for several other caption standards that other SDOs have picked : the SMPTE’s SMPTE-TT format, the EBU’s EBU-TT format, and the DASH Industry Forum’s use of SMPTE-TT. SMPTE-TT has also become the “safe harbour” format for the US legislation on captioning as decided by the FCC. (Note that the FCC requirements for captions on the Web are actually based on a list of features rather than requiring a specific format. But that will be the topic of a different blog post…)
WebVTT is much younger than TTML. TTML was developed as an interchange format among caption authoring systems. WebVTT was built for rendering in Web browsers and with HTML5 in mind. It meets the requirements of the <track> element and supports more than just captions/subtitles. WebVTT is popular with browser developers and has already been implemented in all major browsers (Firefox Nightly is the last to implement it – all others have support already released).
As we can see and as has been proven by the HTML spec and multiple other specs : browsers don’t wait for specifications to have W3C Recommendation status before they implement them. Nor do they really care about the status of a spec – what they care about is whether a spec makes sense for the Web developer and user communities and whether it fits in the Web platform. WebVTT has obviously achieved this status, even with an evolving spec. (Note that the spec tries very hard not to break backwards compatibility, thus all past implementations will at least be compatible with the more basic features of the spec.)
Given that Web browsers don’t need WebVTT to become a W3C standard, why then should we spend effort in moving the spec through the W3C process to become a W3C Recommendation ?
The modern Web is now much bigger than just Web browsers. Web specifications are being used in all kinds of devices including TV set-top boxes, phone and tablet apps, and even unexpected devices such as white goods. Videos are increasingly omnipresent thus exposing deaf and hard-of-hearing users to ever-growing challenges in interacting with content on diverse devices. Some of these devices will not use auto-updating software but fixed versions so can’t easily adapt to new features. Thus, caption producers (both commercial and community) need to be able to author captions (and other video accessibility content as defined by the HTML5 element) towards a feature set that is clearly defined to be supported by such non-updating devices.
Understandably, device vendors in this space have a need to build their technology on standardised specifications. SDOs for such device technologies like to reference fixed specifications so the feature set is not continually updating. To reference WebVTT, they could use a snapshot of the specification at any time and reference that, but that’s not how SDOs work. They prefer referencing an officially sanctioned and tested version of a specification – for a W3C specification that means creating a W3C Recommendation of the WebVTT spec.
Taking WebVTT on a W3C recommendation track is actually advantageous for browsers, too, because a test suite will have to be developed that proves that features are implemented in an interoperable manner. In summary, I can see the advantages and personally support the effort to take WebVTT through to a W3C Recommendation.
Choice of Working Group
FAIK this is the first time that a specification developed in a Community Group is being moved into the recommendation track. This is something that has been expected when the W3C created CGs, but not something that has an established process yet.
The first question of course is which WG would take it through to Recommendation ? Would we create a new Working Group or find an existing one to move the specification through ? Since WGs involve a lot of overhead, the preference was to add WebVTT to the charter of an existing WG. The two obvious candidates were the HTML WG and the TT-WG – the first because it’s where WebVTT originated and the latter because it’s the closest thematically.
Adding a deliverable to a WG is a major undertaking. The TT-WG is currently in the process of re-chartering and thus a suggestion was made to add WebVTT to the milestones of this WG. TBH that was not my first choice. Since I’m already an editor in the HTML WG and WebVTT is very closely related to HTML and can be tested extensively as part of HTML, I preferred the HTML WG. However, adding WebVTT to the TT-WG has some advantages, too.
Since TTML is an exchange format, lots of captions that will be created (at least professionally) will be in TTML and TTML-related formats. It makes sense to create a mapping from TTML to WebVTT for rendering in browsers. The expertise of both, TTML and WebVTT experts is required to develop a good mapping – as has been shown when we developed the mapping from CEA608/708 to WebVTT. Also, captioning experts are already in the TT-WG, so it helps to get a second set of eyes onto WebVTT.
A disadvantage of moving a specification out of a CG into a WG is, however, that you potentially lose a lot of the expertise that is already involved in the development of the spec. People don’t easily re-subscribe to additional mailing lists or want the additional complexity of involving another community (see e.g. this email).
So, a good process needs to be developed to allow everyone to contribute to the spec in the best way possible without requiring duplicate work. How can we do that ?
The forthcoming process
At TPAC the TT-WG discussed for several hours what the next steps are in taking WebVTT through the TT-WG to recommendation status (agenda with slides). I won’t bore you with the different views – if you are keen, you can read the minutes.
What I came away with is the following process :
- Fix a few more bugs in the CG until we’re happy with the feature set in the CG. This should match the feature set that we realistically expect devices to implement for a first version of the WebVTT spec.
- Make a FSA (Final Specification Agreement) in the CG to create a stable reference and a clean IPR position.
- Assuming that the TT-WG’s charter has been approved with WebVTT as a milestone, we would next bring the FSA specification into the TT-WG as FPWD (First Public Working Draft) and immediately do a Last Call which effectively freezes the feature set (this is possible because there has already been wide community review of the WebVTT spec) ; in parallel, the CG can continue to develop the next version of the WebVTT spec with new features (just like it is happening with the HTML5 and HTML5.1 specifications).
- Develop a test suite and address any issues in the Last Call document (of course, also fix these issues in the CG version of the spec).
- As per W3C process, substantive and minor changes to Last Call documents have to be reported and raised issues addressed before the spec can progress to the next level : Candidate Recommendation status.
- For the next step – Proposed Recommendation status – an implementation report is necessary, and thus the test suite needs to be finalized for the given feature set. The feature set may also be reduced at this stage to just the ones implemented interoperably, leaving any other features for the next version of the spec.
- The final step is Recommendation status, which simply requires sufficient support and endorsement by W3C members.
The first version of the WebVTT spec naturally has a focus on captioning (and subtitling), since this has been the dominant use case that we have focused on this far and it’s the part that is the most compatibly implemented feature set of WebVTT in browsers. It’s my expectation that the next version of WebVTT will have a lot more features related to audio descriptions, chapters and metadata. Thus, this seems a good time for a first version feature freeze.
There are still several obstacles towards progressing WebVTT as a milestone of the TT-WG. Apart from the need to get buy-in from the TT-WG, the TT-CG, and the AC (Adivisory Committee who have to approve the new charter), we’re also looking at the license of the specification document.
The CG specification has an open license that allows creating derivative work as long as there is attribution, while the W3C document license for documents on the recommendation track does not allow the creation of derivative work unless given explicit exceptions. This is an issue that is currently being discussed in the W3C with a proposal for a CC-BY license on the Recommendation track. However, my view is that it’s probably ok to use the different document licenses : the TT-WG will work on WebVTT 1.0 and give it a W3C document license, while the CG starts working on the next WebVTT version under the open CG license. It probably actually makes sense to have a less open license on a frozen spec.
Making the best of a complicated world
WebVTT is now proposed as part of the recharter of the TT-WG. I have no idea how complicated the process will become to achieve a W3C WebVTT 1.0 Recommendation, but I am hoping that what is outlined above will be workable in such a way that all of us get to focus on progressing the technology.
At TPAC I got the impression that the TT-WG is committed to progressing WebVTT to Recommendation status. I know that the TT-CG is committed to continue developing WebVTT to its full potential for all kinds of media-time aligned content with new kinds already discussed at FOMS. Let’s enable both groups to achieve their goals. As a consequence, we will allow the two formats to excel where they do : TTML as an interchange format and WebVTT as a browser rendering format.
-
ISO-9660 Compromise, Part 2 : Finding Root
25 octobre 2021, par Multimedia Mike — GeneralA long time ago, I dashed off a quick blog post with a curious finding after studying the ISO-9660 spec : The format stores multi-byte numbers in a format I termed “omni-endian”– the committee developing the format apparently couldn’t come to an agreement on this basic point regarding big- vs. little-endian encoding (I’m envisioning something along the lines of “tastes great ! … less filling !” in the committee meetings).
I recently discovered another bit of compromise in the ISO-9660 spec : It seems that there are 2 different methods for processing the directory structure. That means it’s incumbent upon ISO-9660 creation software to fill in the data structures to support both methods, because some ISO-reading programs out there rely on one set of data structures while the rest prefer to read the other set.
Background
As a refresher, the “ISO” extension of an ISO file refers to the ISO-9660 specification. This is a type of read-only filesystem (i.e, the filesystem is created once and never updated after initial creation) for the purpose of storing on a read-only medium, often an optical disc (CD-ROM, DVD-ROM). The level of nostalgic interest I display for the ISO-9660 filesystem reminds me of my computer science curriculum professors from the mid-90s reminiscing about ye olden days of punchcard programming, but such is my lot. I’m probably also alone in my frustration of seeing rips of, e.g., GameCube or Xbox or 3DO games being tagged with the extension .ISO since those systems use different read-only filesystems.
I recently fell in with an odd bunch called the eXoDOS project and was trying to help fill in a few gaps. One request was a 1994 game called Power Drive for DOS.

My usual CD-ROM ripping method (for the data track) is a simple ‘dd’ command from a Linux command line to copy the string of raw sectors. However, it turned out to be unusually difficult to open the resulting ISO. A few of the the options I know of worked but most didn’t. What’s the difference ?
Methods that work :
- Mounting the file with the Linux iso9660 kernel module, i.e.,
mount -t iso9660 /dev/optical-drive /mnt
or
mount -t iso9660 -o loop /path/to/Power-Drive.iso /mnt
- Directory Opus
- Windows 10 can read the filesystem when reading the physical disc
- Windows 10 can burn the ISO image to a new CD (“right click” -> “Burn disc image”) ; this method does not modify any of the existing sectors but did append 149 additional empty sectors
Methods that don’t work :
- fuseiso
- Dosbox
- Winrar
- 7zip
- Daemon Tools
- Imgburn
- Internet Archive’s ISO lister (“View contents” on the ISO file)
Understanding The Difference
I think I might have a handle on why some tools are able to process this disc while most can’t. There appears to be 2 sets of data structures to describe the base of the filesystem : A root directory, and a path table. These both occur in the first substantive sector of the ISO-9660 filesystem, usually sector 16.
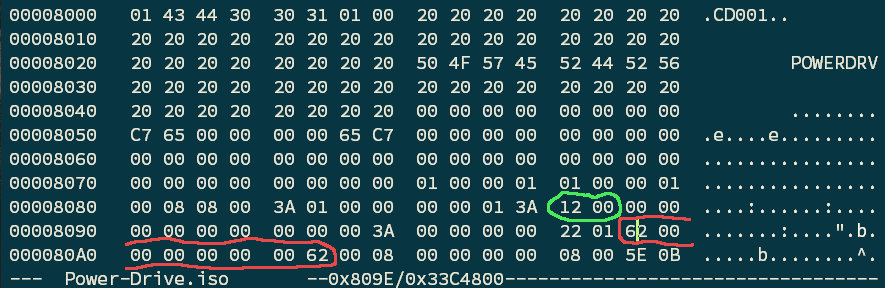
A compact disc can be abstractly visualized as a long string of sectors, each one 2,352 bytes long. (See my Grand Unified Theory of Compact Disc post for deeper discussion.) A CD-ROM data track will contain 2048 bytes of data. Thus, sector 16 appears at 0x8000 of an ISO filesystem. I like the clarity of this description of the ISO-9660 spec. It shows that the path table is defined at byte 140 (little-endian ; big comes later) and location of the root directory is at byte 158. Thus, these locations generally occur at 0x808c and 0x809e.

Primary Volume Descriptor
The path table is highlighted in green and the root directory record is highlighted in red. These absolute locations are specified in sectors. So the path table is located at sector 0x12 = offset 0x9000 in the image, while the root directory record is supposed to be at sector 0x62 = 0x31000. Checking into those sectors, it turns out that the path table is valid while the root directory record is invalid. Thus, any tool that relies on the path table will be successful in interpreting the disc, while tools that attempt to recursively traverse starting from root directory record are gonna have a bad time.
Since I was able to view the filesystem with a few different tools, I know what the root directory contains. Searching for those filenames reveals that the root directory was supposed to point to the next sector, number 0x63. So this was a bizarre off-by-1 error on the part of the ISO creation tool. Maybe. I manually corrected 0x62 -> 0x63 and that fixed the interaction with fuseiso, but not with other tools. So there may have been some other errors. Note that a quick spot-check of another, functional ISO revealed that this root directory sector is supposed to be exact, not 1-indexed.
Upon further inspection, I noticed that, while fuseiso appeared to work with that one patch, none of the files returned correct data, and none of the directories contained anything. That’s when I noticed that ALL of the sector locations described in the various directory and file records are off by 1 !
Further Investigation
I have occasionally run across ISO images on the Internet Archive that return the error about not being able to read the contents when trying to “View contents” (error text : “failed to obtain file list from xyz.iso”, as seen with this ISO). Too bad I didn’t make a record of them because I would be interested to see if they have the same corruption.
Eventually, I’ll probably be able to compile an archive of deviant ISO-9660 images. A few months ago, I was processing a large collection from IA and found a corrupted ISO which had a cycle, i.e., the subdirectory pointed to a parent directory, which caused various ISO tools to loop forever. Just one of those things that is “never supposed to happen”, so why write code to deal with it gracefully ?
See Also
The post ISO-9660 Compromise, Part 2 : Finding Root first appeared on Breaking Eggs And Making Omelettes.
- Mounting the file with the Linux iso9660 kernel module, i.e.,
-
What is Audience Segmentation ? The 5 Main Types & Examples
16 novembre 2023, par Erin — Analytics Tips