Recherche avancée
Médias (1)
-

La conservation du net art au musée. Les stratégies à l’œuvre
26 mai 2011
Mis à jour : Juillet 2013
Langue : français
Type : Texte
Autres articles (76)
-
Gestion des droits de création et d’édition des objets
8 février 2011, parPar défaut, beaucoup de fonctionnalités sont limitées aux administrateurs mais restent configurables indépendamment pour modifier leur statut minimal d’utilisation notamment : la rédaction de contenus sur le site modifiables dans la gestion des templates de formulaires ; l’ajout de notes aux articles ; l’ajout de légendes et d’annotations sur les images ;
-
Activation de l’inscription des visiteurs
12 avril 2011, parIl est également possible d’activer l’inscription des visiteurs ce qui permettra à tout un chacun d’ouvrir soit même un compte sur le canal en question dans le cadre de projets ouverts par exemple.
Pour ce faire, il suffit d’aller dans l’espace de configuration du site en choisissant le sous menus "Gestion des utilisateurs". Le premier formulaire visible correspond à cette fonctionnalité.
Par défaut, MediaSPIP a créé lors de son initialisation un élément de menu dans le menu du haut de la page menant (...) -
Des sites réalisés avec MediaSPIP
2 mai 2011, parCette page présente quelques-uns des sites fonctionnant sous MediaSPIP.
Vous pouvez bien entendu ajouter le votre grâce au formulaire en bas de page.
Sur d’autres sites (9126)
-
VP8 for Real-time Video Applications
15 février 2011, par noreply@blogger.com (John Luther)With the growing interest in videoconferencing on the web platform, it’s a good time to explore the features of VP8 that make it an exceptionally good codec for real-time applications like videoconferencing.
VP8 Design History & Features
Real-time applications were a primary use case when VP8 was designed. The VP8 encoder has features specifically engineered to overcome the challenges inherent in compressing and transmitting real-time video data.
- Processor-adaptive encoding. 16 encoder complexity levels automatically (or manually) adjust encoder features such as motion search strategy, quantizer optimizations, and loop filtering strength.
- Encoder can be configured to use a target percentage of the host CPU.
Ability to measure the time taken to encode each frame and adjust encoder complexity dynamically to keep the encoding time per frame constant - Robust error recovery (packet retransmission, forward error correction, recovery frame/new keyframe requests)
- Temporal scalability (i.e., a single video bitstream that can degrade as needed depending on a participant’s available bandwidth)
- Highly efficient decoding performance on low-power devices. Conventional video technology has grown to a state of complexity where dedicated hardware chips are needed to make it work well. With VP8, software-based solutions have proven to meet customer needs without requiring specialized hardware.
For a more information about real-time video features in VP8, see the slide presentation by WebM Project engineer Paul Wilkins (PDF file).
Commercially Available Products
Millions of people around the world have been using VP7/8 for video chat for years. VP8 is deployed in some of today’s most popular consumer videoconferencing applications, including Skype (group video calling), Sightspeed, ooVoo and Logitech Vid. All of these vendors are active WebM project supporters. VP8’s predecessor, VP7, has been used in Skype video calling since 2005 and is supported in the new Skype app for iPhone. Other real-time VP8 implementations are coming soon, including ooVoo, and VP8 will play a leading role in Google’s plans for real-time applications on the web platform.
Real-time applications will be extremely important as the web platform matures. The WebM community has made significant improvements in VP8 for real-time use cases since our launch and will continue to do so in the future.
John Luther is Product Manager of the WebM Project.
-
The use cases for a element in HTML
27 novembre 2012, par silviaThe W3C HTML WG and the WHATWG are currently discussing the introduction of a <main> element into HTML.
The <main> element has been proposed by Steve Faulkner and is specified in a draft extension spec which is about to be accepted as a FPWD (first public working draft) by the W3C HTML WG. This implies that the W3C HTML WG will be looking for implementations and for feedback by implementers on this spec.
I am supportive of the introduction of a <main> element into HTML. However, I believe that the current spec and use case list don’t make a good enough case for its introduction. Here are my thoughts.
Main use case : accessibility
In my opinion, the main use case for the introduction of <main> is accessibility.
Like any other users, when blind users want to perceive a Web page/application, they need to have a quick means of grasping the content of a page. Since they cannot visually scan the layout and thus determine where the main content is, they use accessibility technology (AT) to find what is known as “landmarks”.
“Landmarks” tell the user what semantic content is on a page : a header (such as a banner), a search box, a navigation menu, some asides (also called complementary content), a footer, …. and the most important part : the main content of the page. It is this main content that a blind user most often wants to skip to directly.
In the days of HTML4, a hidden “skip to content” link at the beginning of the Web page was used as a means to help blind users access the main content.
In the days of ARIA, the aria @role=main enables authors to avoid a hidden link and instead mark the element where the main content begins to allow direct access to the main content. This attribute is supported by AT – in particular screen readers – by making it part of the landmarks that AT can directly skip to.
Both the hidden link and the ARIA @role=main approaches are, however, band aids : they are being used by those of us that make “finished” Web pages accessible by adding specific extra markup.
A world where ARIA is not necessary and where accessibility developers would be out of a job because the normal markup that everyone writes already creates accessible Web sites/applications would be much preferable over the current world of band-aids.
Therefore, to me, the primary use case for a <main> element is to achieve exactly this better world and not require specialized markup to tell a user (or a tool) where the main content on a page starts.
An immediate effect would be that pages that have a <main> element will expose a “main” landmark to blind and vision-impaired users that will enable them to directly access that main content on the page without having to wade through other text on the page. Without a <main> element, this functionality can currently only be provided using heuristics to skip other semantic and structural elements and is for this reason not typically implemented in AT.
Other use cases
The <main> element is a semantic element not unlike other new semantic elements such as <header>, <footer>, <aside>, <article>, <nav>, or <section>. Thus, it can also serve other uses where the main content on a Web page/Web application needs to be identified.
Data mining
For data mining of Web content, the identification of the main content is one of the key challenges. Many scholarly articles have been published on this topic. This stackoverflow article references and suggests a multitude of approaches, but the accepted answer says “there’s no way to do this that’s guaranteed to work”. This is because Web pages are inherently complex and many <div>, <p>, <iframe> and other elements are used to provide markup for styling, notifications, ads, analytics and other use cases that are necessary to make a Web page complete, but don’t contribute to what a user consumes as semantically rich content. A <main> element will allow authors to pro-actively direct data mining tools to the main content.
Search engines
One particularly important “data mining” tool are search engines. They, too, have a hard time to identify which sections of a Web page are more important than others and employ many heuristics to do so, see e.g. this ACM article. Yet, they still disappoint with poor results pointing to findings of keywords in little relevant sections of a page rather than ranking Web pages higher where the keywords turn up in the main content area. A <main> element would be able to help search engines give text in main content areas a higher weight and prefer them over other areas of the Web page. It would be able to rank different Web pages depending on where on the page the search words are found. The <main> element will be an additional hint that search engines will digest.
Visual focus
On small devices, the display of Web pages designed for Desktop often causes confusion as to where the main content can be found and read, in particular when the text ends up being too small to be readable. It would be nice if browsers on small devices had a functionality (maybe a default setting) where Web pages would start being displayed as zoomed in on the main content. This could alleviate some of the headaches of responsive Web design, where the recommendation is to show high priority content as the first content. Right now this problem is addressed through stylesheets that re-layout the page differently depending on device, but again this is a band-aid solution. Explicit semantic markup of the main content can solve this problem more elegantly.
Styling
Finally, naturally, <main> would also be used to style the main content differently from others. You can e.g. replace a semantically meaningless <div id=”main”> with a semantically meaningful <main> where their position is identical. My analysis below shows, that this is not always the case, since oftentimes <div id=”main”> is used to group everything together that is not the header – in particular where there are multiple columns. Thus, the ease of styling a <main> element is only a positive side effect and not actually a real use case. It does make it easier, however, to adapt the style of the main content e.g. with media queries.
Proposed alternative solutions
It has been proposed that existing markup serves to satisfy the use cases that <main> has been proposed for. Let’s analyse these on some of the most popular Web sites. First let’s list the propsed algorithms.
Proposed solution No 1 : Scooby-Doo
On Sat, Nov 17, 2012 at 11:01 AM, Ian Hickson <ian@hixie.ch> wrote : | The main content is whatever content isn’t | marked up as not being main content (anything not marked up with <header>, | <aside>, <nav>, etc).
This implies that the first element that is not a <header>, <aside>, <nav>, or <footer> will be the element that we want to give to a blind user as the location where they should start reading. The algorithm is implemented in https://gist.github.com/4032962.
Proposed solution No 2 : First article element
On Sat, Nov 17, 2012 at 8:01 AM, Ian Hickson <ian@hixie.ch> wrote : | On Thu, 15 Nov 2012, Ian Yang wrote : | > | > That’s a good idea. We really need an element to wrap all the <p>s, | > <ul>s, <ol>s, <figure>s, <table>s ... etc of a blog post. | | That’s called <article>.
This approach identifies the first <article> element on the page as containing the main content. Here’s the algorithm for this approach.
Proposed solution No 3 : An example heuristic approach
The readability plugin has been developed to make Web pages readable by essentially removing all the non-main content from a page. An early source of readability is available. This demonstrates what a heuristic approach can perform.
Analysing alternative solutions
Comparison
I’ve picked 4 typical Websites (top on Alexa) to analyse how these three different approaches fare. Ideally, I’d like to simply apply the above three scripts and compare pictures. However, since the semantic HTML5 elements <header>, <aside>, <nav>, and <footer> are not actually used by any of these Web sites, I don’t actually have this choice.
So, instead, I decided to make some assumptions of where these semantic elements would be used and what the outcome of applying the first two algorithms would be. I can then compare it to the third, which is a product so we can take screenshots.
Google.com
http://google.com – search for “Scooby Doo”.
The search results page would likely be built with :
- a <nav> menu for the Google bar
- a <header> for the search bar
- another <header> for the login section
- another <nav> menu for the search types
- a <div> to contain the rest of the page
- a <div> for the app bar with the search number
- a few <aside>s for the left and right column
- a set of <article>s for the search results
“Scooby Doo” would find the first element after the headers as the “main content”. This is the element before the app bar in this case. Interestingly, there is a <div @id=main> already in the current Google results page, which “Scooby Doo” would likely also pick. However, there are a nav bar and two asides in this div, which clearly should not be part of the “main content”. Google actually placed a @role=main on a different element, namely the one that encapsulates all the search results.“First Article” would find the first search result as the “main content”. While not quite the same as what Google intended – namely all search results – it is close enough to be useful.
The “readability” result is interesting, since it is not able to identify the main text on the page. It is actually aware of this problem and brings a warning before displaying this page :

Facebook.com
A user page would likely be built with :
- a <header> bar for the search and login bar
- a <div> to contain the rest of the page
- an <aside> for the left column
- a <div> to contain the center and right column
- an <aside> for the right column
- a <header> to contain the center column “megaphone”
- a <div> for the status posting
- a set of <article>s for the home stream
“Scooby Doo” would find the first element after the headers as the “main content”. This is the element that contains all three columns. It’s actually a <div @id=content> already in the current Facebook user page, which “Scooby Doo” would likely also pick. However, Facebook selected a different element to place the @role=main : the center column.“First Article” would find the first news item in the home stream. This is clearly not what Facebook intended, since they placed the @role=main on the center column, above the first blog post’s title. “First Article” would miss that title and the status posting.
The “readability” result again disappoints but warns that it failed :

YouTube.com
A video page would likely be built with :
- a <header> bar for the search and login bar
- a <nav> for the menu
- a <div> to contain the rest of the page
- a <header> for the video title and channel links
- a <div> to contain the video with controls
- a <div> to contain the center and right column
- an <aside> for the right column with an <article> per related video
- an <aside> for the information below the video
- a <article> per comment below the video
“Scooby Doo” would find the first element after the headers as the “main content”. This is the element that contains the rest of the page. It’s actually a <div @id=content> already in the current YouTube video page, which “Scooby Doo” would likely also pick. However, YouTube’s related videos and comments are unlikely to be what the user would regard as “main content” – it’s the video they are after, which generously has a <div id=watch-player>.“First Article” would find the first related video or comment in the home stream. This is clearly not what YouTube intends.
The “readability” result is not quite as unusable, but still very bare :

Wikipedia.com
http://wikipedia.com (“Overscan” page)
A Wikipedia page would likely be built with :
- a <header> bar for the search, login and menu items
- a <div> to contain the rest of the page
- an &ls; article> with title and lots of text
- <article> an <aside> with the table of contents
- several <aside>s for the left column
Good news : “Scooby Doo” would find the first element after the headers as the “main content”. This is the element that contains the rest of the page. It’s actually a <div id=”content” role=”main”> element on Wikipedia, which “Scooby Doo” would likely also pick.“First Article” would find the title and text of the main element on the page, but it would also include an <aside>.
The “readability” result is also in agreement.

Results
In the following table we have summarised the results for the experiments :
Site Scooby-Doo First article Readability Google.com FAIL SUCCESS FAIL Facebook.com FAIL FAIL FAIL YouTube.com FAIL FAIL FAIL Wikipedia.com SUCCESS SUCCESS SUCCESS Clearly, Wikipedia is the prime example of a site where even the simple approaches find it easy to determine the main content on the page. WordPress blogs are similarly successful. Almost any other site, including news sites, social networks and search engine sites are petty hopeless with the proposed approaches, because there are too many elements that are used for layout or other purposes (notifications, hidden areas) such that the pre-determined list of semantic elements that are available simply don’t suffice to mark up a Web page/application completely.
Conclusion
It seems that in general it is impossible to determine which element(s) on a Web page should be the “main” piece of content that accessibility tools jump to when requested, that a search engine should put their focus on, or that should be highlighted to a general user to read. It would be very useful if the author of the Web page would provide a hint through a <main> element where that main content is to be found.
I think that the <main> element becomes particularly useful when combined with a default keyboard shortcut in browsers as proposed by Steve : we may actually find that non-accessibility users will also start making use of this shortcut, e.g. to get to videos on YouTube pages directly without having to tab over search boxes and other interactive elements, etc. Worthwhile markup indeed.
-
Alias Artifacts
26 avril 2013, par Multimedia Mike — GeneralThroughout my own life, I have often observed that my own sense of nostalgia has a window that stretches about 10-15 years past from the current moment. Earlier this year, I discovered the show “Alias” and watched through the entire series thanks to Amazon Prime Instant Video (to be fair, I sort of skimmed the fifth and final season which I found to be horribly dull, or maybe franchise fatigue had set in). The show originally aired from 2001-2006 so I found that it fit well within the aforementioned nostalgia window.

But what was it, exactly, about the show that triggered nostalgia ? The computers, of course ! The show revolved around spies and espionage and cutting-edge technology necessarily played a role. The production designer for the series must have decided that Unix/Linux == awesome hacking and so many screenshots featured Linux.
Since this is still nominally a multimedia blog, I’ll start of the screenshot recon with an old multimedia player. Here is a vintage Mac OS desktop running an ancient web browser (probably Netscape) that’s playing a full-window video (probably QuickTime embedded directly into the browser).

Click for larger image
Let’s jump right into the Linux side of things. This screenshot makes me particularly sentimental since this is exactly what a stock Linux/KDE desktop looked like circa 2001-2003 and is more or less what I would have worked with on my home computer at the time :

Click for larger image
Studying that screenshot, we see that the user logs in as root, even to the desktop environment. Poor security practice ; I would expect better from a bunch of spooks.
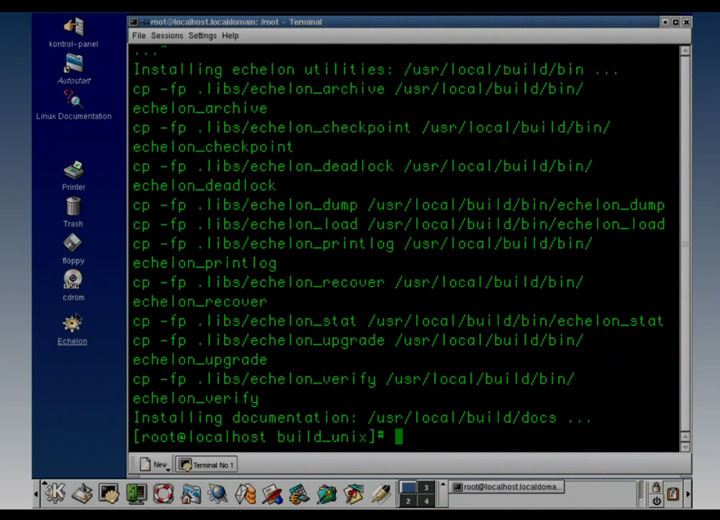
Echelon
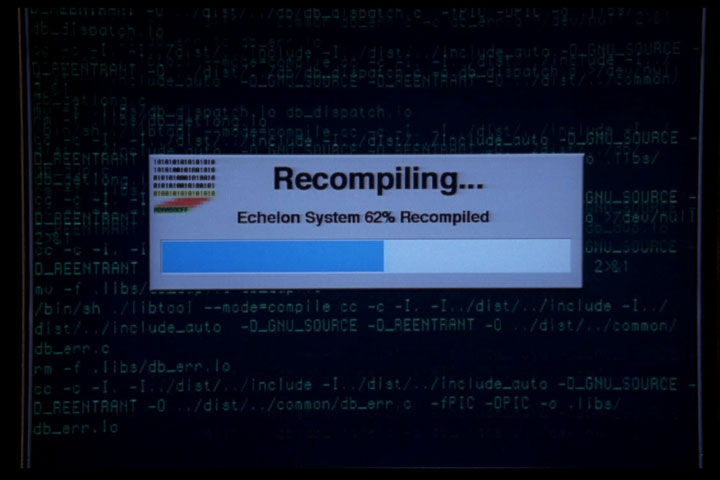
Look at the terminal output in the above screenshot– it’s building a program named Echelon, an omniscient spy tool inspired by a real-world surveillance network of the same name. In the show, Echelon is used to supply plot-convenient intelligence. At one point, some antagonists get their hands on the Echelon source code and seek to compile it. When they do, they will have access to the vast surveillance network. If you know anything about how computers work, don’t think about that too hard.Anyway, it’s interesting to note that Echelon is a properly autotool’d program– when the bad guys finally got Echelon, installation was just a ‘make install’ command away. The compilation was very user-friendly, though, as it would pop up a nice dialog box showing build progress :

Click for larger image
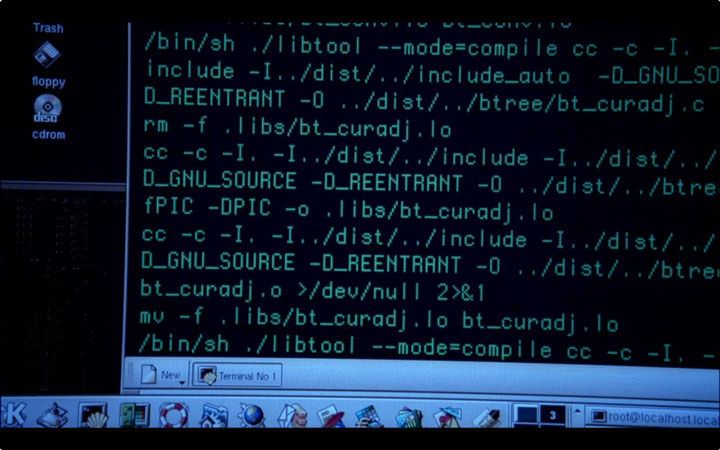
Examining the build lines in both that screenshot and the following lines, we can see that Echelon cares about files such as common/db_err.c and bt_curadj.c :

Click for larger image
A little googling reveals that these files both belong to the Berkeley DB library. That works ; I can imagine a program like this leveraging various database packages.
Computer Languages
The Echelon source code stuff comes from episode 2.11 : “A Higher Echelon”. While one faction had gotten a hold of the actual Echelon source code, a rival faction had abducted the show’s resident uber-nerd and, learning that they didn’t actually receive the Echelon code, force the nerd to re-write Echelon from scratch. Which he then proceeds to do…

Click for larger image
The code he’s examining there appears to be C code that has something to do with joystick programming (JS_X_0, JS_Y_1, etc.). An eagle-eyed IMDb user contributed the trivia that he is looking at the file /usr/include/Linux/joystick.h.
Getting back to the plot, how could the bad buys possibly expect him to re-write a hugely complex piece of software from scratch ? You might think this is the height of absurdity for a computer-oriented story. You’ll be pleased to know that the writers agreed with that assessment since, when the program was actually executed, it claimed to be Echelon, but that broke into a game of Pong (or some simple game). Suddenly, it makes perfect sense why the guy was looking at the joystick header file.
This is the first bit of computer-oriented fun that I captured when I was watching the series :

Click for larger image
This printout purports to be a “mainframe log summary”. After some plot-advancing text about a security issue, it proceeds to dump out some Java source code.
SSH
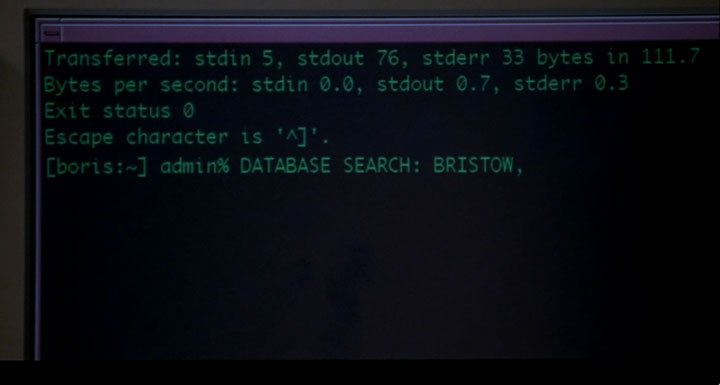
Secure Shell (SSH) frequently showed up. Here’s a screenshot in which a verbose ‘ssh -v’ connection has just been closed, while a telnet command has apparently just been launched (evidenced by “Escape character is ‘^]’.”) :

Click for larger image
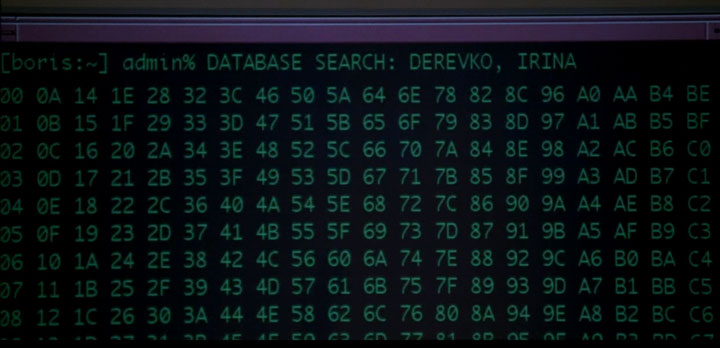
This is followed by some good old Hollywood Hacking in which a free-form database command is entered through any available command line interface :

Click for larger image
I don’t remember the episode details, but I’m pretty sure the output made perfect sense to the character typing the command. Here’s another screenshot where the SSH client pops up an extra-large GUI dialog element to notify the user that it’s currently negotiating with the host :

Click for larger image
Now that I look at that screenshot a little more closely, it appears to be a Win95/98 program. I wonder if there was an SSH client that actually popped up that gaudy dialog.
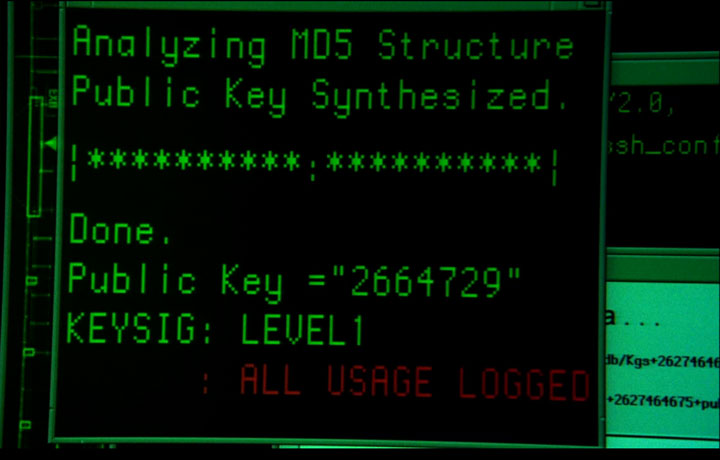
There’s a lot of gibberish in this screenshot and I wish I had written down some details about what it represented according to the episode’s plot :

Click for larger image
It almost sounds like they were trying to break into a network computer. Analyzing MD5 structure… public key synthesized. To me, the funniest feature is the 7-digit public key. I’m a bit rusty on the math of the RSA cryptosystem, but intuitively, it seems that the public and private keys need to be of roughly equal lengths. I.e., the private key in this scenario would also be 7 digits long.
Gadgets
Various devices and gadgets were seen at various junctures in the show. Here’s a tablet computer from back when tablet computers seemed like fantastical (albeit stylus-requiring) devices– the Fujitsu Stylistic 2300 :

Click for larger image
Here’s a videophone from an episode that aired in 2005. The specific model is the Packet8 DV326 (MSRP of US$500). As you can see from the screenshot, it can do 384 kbps both down and up.

Click for larger image
I really regret not writing down the episode details surrounding this gadget. I just know that it was critical that the good guys get it and keep from falling into the hands of the bad guys.

Click for larger image
As you can see, the (presumably) deadly device contains a Samsung chip and a Lexar chip. I have to wonder what device the production crew salvaged this from (probably just an old cell phone).
Other Programs
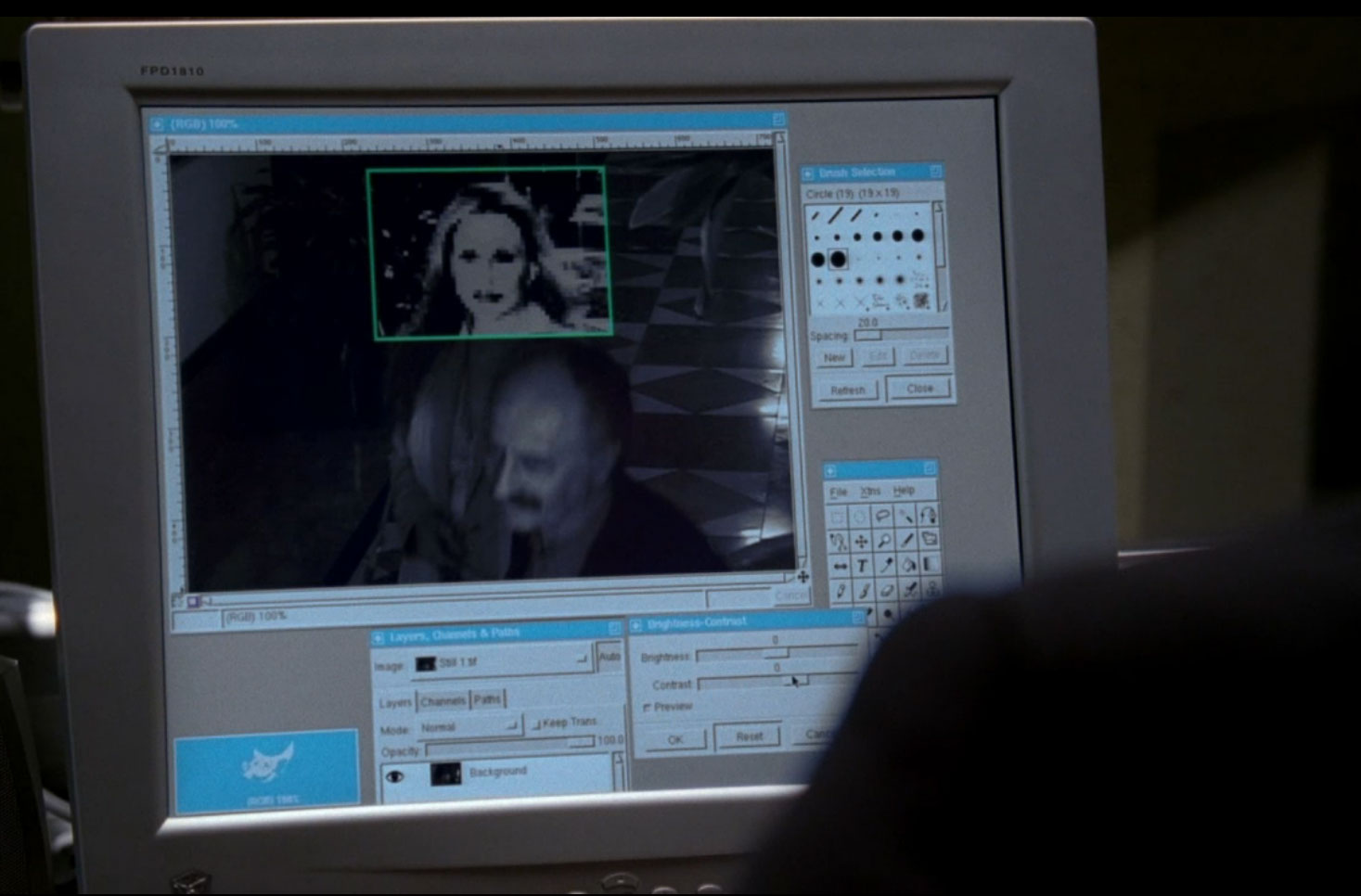
The GIMP photo editor makes an appearance while scrubbing security camera footage, and serves as the magical Enhance Button (at least they slung around the term “gamma”) :

Click for larger image
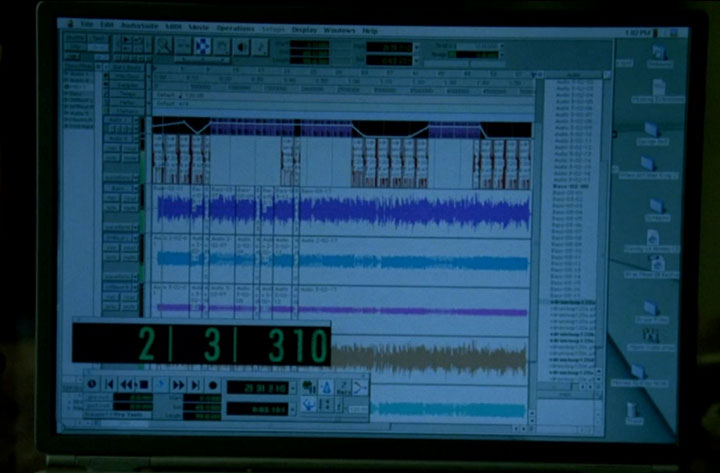
I have no idea what MacOS-based audio editing program this is. Any ideas ?

Click for larger image
FTP shows up in episode 2.12, “The Getaway”. It’s described as a “secure channel” for communication, which is quite humorous to anyone versed in internet technology.

Click for larger image