Recherche avancée
Médias (1)
-

The Great Big Beautiful Tomorrow
28 octobre 2011, par
Mis à jour : Octobre 2011
Langue : English
Type : Texte
Autres articles (59)
-
Support audio et vidéo HTML5
10 avril 2011MediaSPIP utilise les balises HTML5 video et audio pour la lecture de documents multimedia en profitant des dernières innovations du W3C supportées par les navigateurs modernes.
Pour les navigateurs plus anciens, le lecteur flash Flowplayer est utilisé.
Le lecteur HTML5 utilisé a été spécifiquement créé pour MediaSPIP : il est complètement modifiable graphiquement pour correspondre à un thème choisi.
Ces technologies permettent de distribuer vidéo et son à la fois sur des ordinateurs conventionnels (...) -
HTML5 audio and video support
13 avril 2011, parMediaSPIP uses HTML5 video and audio tags to play multimedia files, taking advantage of the latest W3C innovations supported by modern browsers.
The MediaSPIP player used has been created specifically for MediaSPIP and can be easily adapted to fit in with a specific theme.
For older browsers the Flowplayer flash fallback is used.
MediaSPIP allows for media playback on major mobile platforms with the above (...) -
De l’upload à la vidéo finale [version standalone]
31 janvier 2010, parLe chemin d’un document audio ou vidéo dans SPIPMotion est divisé en trois étapes distinctes.
Upload et récupération d’informations de la vidéo source
Dans un premier temps, il est nécessaire de créer un article SPIP et de lui joindre le document vidéo "source".
Au moment où ce document est joint à l’article, deux actions supplémentaires au comportement normal sont exécutées : La récupération des informations techniques des flux audio et video du fichier ; La génération d’une vignette : extraction d’une (...)
Sur d’autres sites (6666)
-
How to use youtube-dl inside ffmpeg
3 décembre 2022, par Dương Phương NamI tried to record a live stream video by this code. I add that code inside render.cmd



ffmpeg -i $(youtube-dl -f 95 -g https://www.youtube.com/watch?v=v2_knJ1RwlQ) -c copy render.ts



but i got this error $(youtube-dl : No such file or directory



anyone help me please


-
How to ssh vps and play the video ?
25 juillet 2017, par scrapyI build apache2 on vps,start it,and upload test.mp4 into /var/www/html.
ffplay http://vps_ip/test.mp4I can watch test.mp4 ,maybe there is a other way to play it.
1.ssh root@vps_ip
2.mv /var/www/html/test.mp4 /tmp/test.mp4
3.ffplay /tmp/test.mp4
Could not initialize SDL - No available video device
(Did you set the DISPLAY variable?)libsdl2-dev and sdl are all installed on my vps.
How to ffplay it after sshing login it ? -
ffmpeg, opus encoded sound in webm does not work [on hold]
1er août 2017, par MockarutanI’m having trouble getting Opus encoded sound in the webm container to work. I’m using libopus in ffmpeg.
The file does work in VLC. But not in ffplay or on YouTube. If I take the raw wav data in a wav file and then convert it to Opus/webm with the ffmpeg.exe that comes pre-compiled. It works in VLC, ffplay and YouTube.
So ffmpeg can obviously do it correctly, I must be doing something wrong in my code.
The file my code produces : https://drive.google.com/file/d/0B16rIXjPXJCqcU5HVllIYW1iODg/view?usp=sharing
Edit, More details that I forgot in my frustration : The file can be opened by ffplay and uploaded to youtube (when I interlace it with VP9 video). But the sound is just "ticks", example : https://www.youtube.com/watch?v=j_ShBbuizeo&feature=youtu.be
I have read though all example codes that I know of from ffmpeg, but all of them is in the old API, not the send/receive api, so a big part of the code does not apply anymore. This codes works with all other Codes I’ve tested, including H.264+AAC in mp4, VP8+Opus in ogg and raw PCM F32LE in wav. I would have gone with VP8+Opus in ogg if the license was as straight forward as the webm license
I’ve looked though the source for the ffmpeg.exe command line tool and coped everything applicable in to my code base.
Here is my code : https://pastebin.com/4c999Uz2
#include "encoder.h"
#include <algorithm>
#include <iterator>
extern "C"
{
#include "libavcodec/avcodec.h"
#include "libavdevice/avdevice.h"
#include "libavfilter/avfilter.h"
#include "libavformat/avformat.h"
#include "libavutil/avutil.h"
#include "libavutil/imgutils.h"
#include "libswscale/swscale.h"
#include "libswresample/swresample.h"
enum InfoCodes
{
ENCODED_VIDEO,
ENCODED_AUDIO,
ENCODED_AUDIO_AND_VIDEO,
NOT_ENOUGH_AUDIO_DATA,
};
enum ErrorCodes
{
RES_NOT_MUL_OF_TWO = -1,
ERROR_FINDING_VID_CODEC = -2,
ERROR_CONTEXT_CREATION = -3,
ERROR_CONTEXT_ALLOCATING = -4,
ERROR_OPENING_VID_CODEC = -5,
ERROR_OPENING_FILE = -6,
ERROR_ALLOCATING_FRAME = -7,
ERROR_ALLOCATING_PIC_BUF = -8,
ERROR_ENCODING_FRAME_SEND = -9,
ERROR_ENCODING_FRAME_RECEIVE = -10,
ERROR_FINDING_AUD_CODEC = -11,
ERROR_OPENING_AUD_CODEC = -12,
ERROR_INIT_RESMPL_CONTEXT = -13,
ERROR_ENCODING_SAMPLES_SEND = -14,
ERROR_ENCODING_SAMPLES_RECEIVE = -15,
ERROR_WRITING_HEADER = -16,
ERROR_INIT_AUDIO_RESPAMLER = -17,
};
AVCodecID aud_codec_comp_id = AV_CODEC_ID_OPUS;
AVSampleFormat sample_fmt_comp = AV_SAMPLE_FMT_S16;
AVCodecID aud_codec_id;
AVSampleFormat sample_fmt;
char* compressed_cont = "webm";
AVCodec *aud_codec = NULL;
AVCodecContext *aud_codec_context = NULL;
AVFormatContext *outctx;
AVStream *audio_st;
AVFrame *aud_frame;
SwrContext *audio_swr_ctx;
uint8_t **dst_data = NULL;
AVRational conv_time_base;
int aud_frame_counter;
int dst_nb_samples, src_nb_samples, max_dst_nb_samples;;
int src_rate, dst_rate;
int dst_nb_channels;
int dst_linesize;
void write_error_to_file(const char* name, int value)
{
int buf_size = 100;
char* buf = new char[buf_size];
int ret = av_strerror(value, buf, buf_size);
FILE *f;
fopen_s(&f, name, "w");
if (f != NULL)
{
if (ret != 0)
fprintf(f, "Error erroring: , \n", ret);
else
fprintf(f, "Error code: %s\n", buf);
fclose(f);
}
}
void write_value_to_file(const char* name, float value)
{
FILE *f;
fopen_s(&f, name, "w");
if (f != NULL)
{
fprintf(f, "Value: %f\n", value);
fclose(f);
}
}
char* concat(const char *s1, const char *s2)
{
char *result = (char*)malloc(strlen(s1) + strlen(s2) + 1);
strcpy(result, s1);
strcat(result, s2);
return result;
}
int setup_audio_codec()
{
aud_codec_id = aud_codec_comp_id;
sample_fmt = sample_fmt_comp;
// Fixup audio codec
if (aud_codec == NULL)
{
aud_codec = avcodec_find_encoder(aud_codec_id);
avcodec_register(aud_codec);
}
if (!aud_codec)
return ERROR_FINDING_AUD_CODEC;
return 0;
}
int initialize_audio_stream(AVFormatContext *local_outctx, int sample_rate, int per_frame_audio_samples, int audio_bitrate)
{
aud_codec_context = avcodec_alloc_context3(aud_codec);
if (!aud_codec_context)
return ERROR_CONTEXT_CREATION;
/* select other audio parameters supported by the encoder */
aud_codec_context->bit_rate = audio_bitrate;
aud_codec_context->sample_rate = sample_rate;
aud_codec_context->sample_fmt = sample_fmt;
aud_codec_context->channel_layout = AV_CH_LAYOUT_STEREO;
aud_codec_context->channels = av_get_channel_layout_nb_channels(aud_codec_context->channel_layout);
aud_codec_context->codec = aud_codec;
aud_codec_context->codec_id = aud_codec_id;
AVRational time_base;
time_base.num = per_frame_audio_samples;
time_base.den = aud_codec_context->sample_rate;
aud_codec_context->time_base = time_base;
int ret = avcodec_open2(aud_codec_context, aud_codec, NULL);
if (ret < 0)
return ERROR_OPENING_AUD_CODEC;
local_outctx->audio_codec = aud_codec;
local_outctx->audio_codec_id = aud_codec_id;
audio_st = avformat_new_stream(local_outctx, aud_codec);
avcodec_parameters_from_context(audio_st->codecpar, aud_codec_context);
conv_time_base.num = aud_codec_context->frame_size;
conv_time_base.den = aud_codec_context->sample_rate;
aud_frame = av_frame_alloc();
aud_frame->nb_samples = aud_codec_context->frame_size;
aud_frame->format = aud_codec_context->sample_fmt;
aud_frame->channel_layout = aud_codec_context->channel_layout;
aud_frame->sample_rate = aud_codec_context->sample_rate;
int buffer_size;
if (aud_codec_context->frame_size == 0)
{
buffer_size = per_frame_audio_samples * 2 * 4;
aud_frame->nb_samples = per_frame_audio_samples;
}
else
{
buffer_size = av_samples_get_buffer_size(NULL, aud_codec_context->channels, aud_codec_context->frame_size,
aud_codec_context->sample_fmt, 0);
}
if (av_sample_fmt_is_planar(sample_fmt))
ret = av_frame_get_buffer(aud_frame, buffer_size / 2);
else
ret = av_frame_get_buffer(aud_frame, buffer_size);
if (!aud_frame || ret < 0)
return ERROR_ALLOCATING_FRAME;
audio_swr_ctx = swr_alloc();
if (!audio_swr_ctx)
return ERROR_INIT_AUDIO_RESPAMLER;
/* set options */
av_opt_set_int(audio_swr_ctx, "in_channel_layout", aud_codec_context->channel_layout, 0);
av_opt_set_int(audio_swr_ctx, "in_sample_rate", sample_rate, 0);
av_opt_set_int(audio_swr_ctx, "in_frame_size", per_frame_audio_samples, 0);
av_opt_set_sample_fmt(audio_swr_ctx, "in_sample_fmt", AV_SAMPLE_FMT_FLT, 0);
av_opt_set_int(audio_swr_ctx, "out_channel_layout", aud_codec_context->channel_layout, 0);
av_opt_set_int(audio_swr_ctx, "out_sample_rate", aud_codec_context->sample_rate, 0);
av_opt_set_int(audio_swr_ctx, "out_frame_size", aud_codec_context->frame_size, 0);
av_opt_set_sample_fmt(audio_swr_ctx, "out_sample_fmt", aud_codec_context->sample_fmt, 0);
/* initialize the resampling context */
if ((ret = swr_init(audio_swr_ctx)) < 0)
{
return ERROR_INIT_AUDIO_RESPAMLER;
}
dst_rate = aud_codec_context->sample_rate;
src_rate = sample_rate;
src_nb_samples = per_frame_audio_samples;
dst_nb_samples = aud_codec_context->frame_size;
max_dst_nb_samples = av_rescale_rnd(src_nb_samples, dst_rate, src_rate, AV_ROUND_UP);
dst_nb_channels = av_get_channel_layout_nb_channels(aud_codec_context->channel_layout);
ret = av_samples_alloc_array_and_samples(&dst_data, &dst_linesize, dst_nb_channels, dst_nb_samples, sample_fmt, 0);
aud_frame_counter = 0;
return 0;
}
int initialize_audio_only_encoding(int sample_rate, int per_frame_audio_samples, int audio_bitrate, const char *filename)
{
int ret;
avcodec_register_all();
av_register_all();
outctx = avformat_alloc_context();
char* full_filename;
char* with_dot = concat(filename, ".");
full_filename = concat(with_dot, compressed_cont);
ret = avformat_alloc_output_context2(&outctx, NULL, compressed_cont, full_filename);
free(with_dot);
if (ret < 0)
{
free(full_filename);
return ERROR_CONTEXT_CREATION;
}
ret = setup_audio_codec();
if (ret < 0)
return ret;
// Setup Audio
ret = initialize_audio_stream(outctx, sample_rate, per_frame_audio_samples, audio_bitrate);
if (ret < 0)
return ret;
av_dump_format(outctx, 0, full_filename, 1);
if (!(outctx->oformat->flags & AVFMT_NOFILE))
{
if (avio_open(&outctx->pb, full_filename, AVIO_FLAG_WRITE) < 0)
{
free(full_filename);
return ERROR_OPENING_FILE;
}
}
free(full_filename);
ret = avformat_write_header(outctx, NULL);
if (ret < 0)
return ERROR_WRITING_HEADER;
return 0;
}
int process_encode_loop(AVFormatContext *local_outctx, AVCodecContext *codec_context, AVStream *stream, AVRational time_base, bool flush)
{
int ret;
AVPacket pkt;
av_init_packet(&pkt);
pkt.data = NULL;
pkt.size = 0;
while (true)
{
ret = avcodec_receive_packet(codec_context, &pkt);
if (!ret)
{
pkt.stream_index = stream->index;
av_packet_rescale_ts(&pkt, time_base, stream->time_base);
av_interleaved_write_frame(local_outctx, &pkt);
av_packet_unref(&pkt);
}
if (ret == AVERROR(EAGAIN))
break;
else if (ret == AVERROR_EOF)
break;
else if (ret < 0)
return ERROR_ENCODING_FRAME_RECEIVE;
else if (flush == false)
break;
}
return 0;
}
int write_audio_frame(float_t *aud_sample)
{
int ret;
if (dst_nb_samples > max_dst_nb_samples)
{
av_free(&aud_frame->data[0]);
ret = av_samples_alloc(aud_frame->data, &dst_linesize, dst_nb_channels, dst_nb_samples, sample_fmt, 1);
if (ret < 0)
return ERROR_INIT_AUDIO_RESPAMLER;
max_dst_nb_samples = dst_nb_samples;
}
ret = swr_convert(audio_swr_ctx, dst_data, dst_nb_samples, (const uint8_t **)&aud_sample, src_nb_samples);
if (ret < 0)
{
return ERROR_INIT_AUDIO_RESPAMLER;
}
aud_frame->data[0] = (uint8_t*)dst_data[0];
aud_frame->extended_data[0] = (uint8_t*)dst_data[0];
aud_frame->pts = aud_frame_counter++;
ret = avcodec_send_frame(aud_codec_context, aud_frame);
if (ret < 0)
{
write_error_to_file("AVERROR.txt", ret);
return ERROR_ENCODING_SAMPLES_SEND;
}
ret = process_encode_loop(outctx, aud_codec_context, audio_st, conv_time_base, false);
if (ret < 0)
return ERROR_ENCODING_SAMPLES_RECEIVE;
return ENCODED_AUDIO;
}
int finish_audio_encoding()
{
//fclose(dst_file);
AVPacket pkt;
av_init_packet(&pkt);
pkt.data = NULL;
pkt.size = 0;
fflush(stdout);
int ret = avcodec_send_frame(aud_codec_context, NULL);
if (ret < 0)
return ERROR_ENCODING_FRAME_SEND;
while (true)
{
ret = avcodec_receive_packet(aud_codec_context, &pkt);
if (!ret)
{
if (pkt.pts != AV_NOPTS_VALUE)
pkt.pts = av_rescale_q(pkt.pts, aud_codec_context->time_base, audio_st->time_base);
if (pkt.dts != AV_NOPTS_VALUE)
pkt.dts = av_rescale_q(pkt.dts, aud_codec_context->time_base, audio_st->time_base);
av_write_frame(outctx, &pkt);
av_packet_unref(&pkt);
}
if (ret == -AVERROR(AVERROR_EOF))
break;
else if (ret < 0)
return ERROR_ENCODING_FRAME_RECEIVE;
}
av_write_trailer(outctx);
return 0;
}
void cleanup()
{
if (aud_frame)
{
av_frame_free(&aud_frame);
}
if (outctx)
{
for (int i = 0; i < outctx->nb_streams; i++)
av_freep(&outctx->streams[i]);
avio_close(outctx->pb);
av_free(outctx);
}
if (aud_codec_context)
{
avcodec_close(aud_codec_context);
av_free(aud_codec_context);
}
}
void fill_samples(float_t *dst, int nb_samples, int nb_channels, int sample_rate, float_t *t)
{
int i, j;
float_t tincr = 1.0 / sample_rate;
const float_t c = 2 * M_PI * 440.0;
/* generate sin tone with 440Hz frequency and duplicated channels */
for (i = 0; i < nb_samples; i++) {
*dst = sin(c * *t);
for (j = 1; j < nb_channels; j++)
dst[j] = dst[0];
dst += nb_channels;
*t += tincr;
}
}
int main()
{
int width = 1920;
int height = 1080;
int frame_rate = 30;
float t = 0, tincr = 0, tincr2 = 0;
int sec = 20;
int tot = 3 * width * height;
uint8_t* rgb24Data = new uint8_t[tot];
float_t** aud_samples_planar;
int16_t** aud_samples_s16;
int src_samples_linesize;
int src_nb_samples = 1024;
int src_channels = 2;
int sample_rate = 48000;
uint8_t **src_data = NULL;
int ret;
initialize_audio_only_encoding(48000, src_nb_samples, 256000, "only_sound");
ret = av_samples_alloc_array_and_samples(&src_data, &src_samples_linesize, src_channels,
src_nb_samples, AV_SAMPLE_FMT_FLT, 0);
for (size_t i = 0; i < frame_rate * sec; i++)
{
fill_samples((float *)src_data[0], src_nb_samples, src_channels, sample_rate, &t);
write_audio_frame((float *)src_data[0]);
}
finish_audio_encoding();
cleanup();
return 0;
}
}
</iterator></algorithm>Any any suggestion is appreciated, thanks in Advance !
Some things I tried :
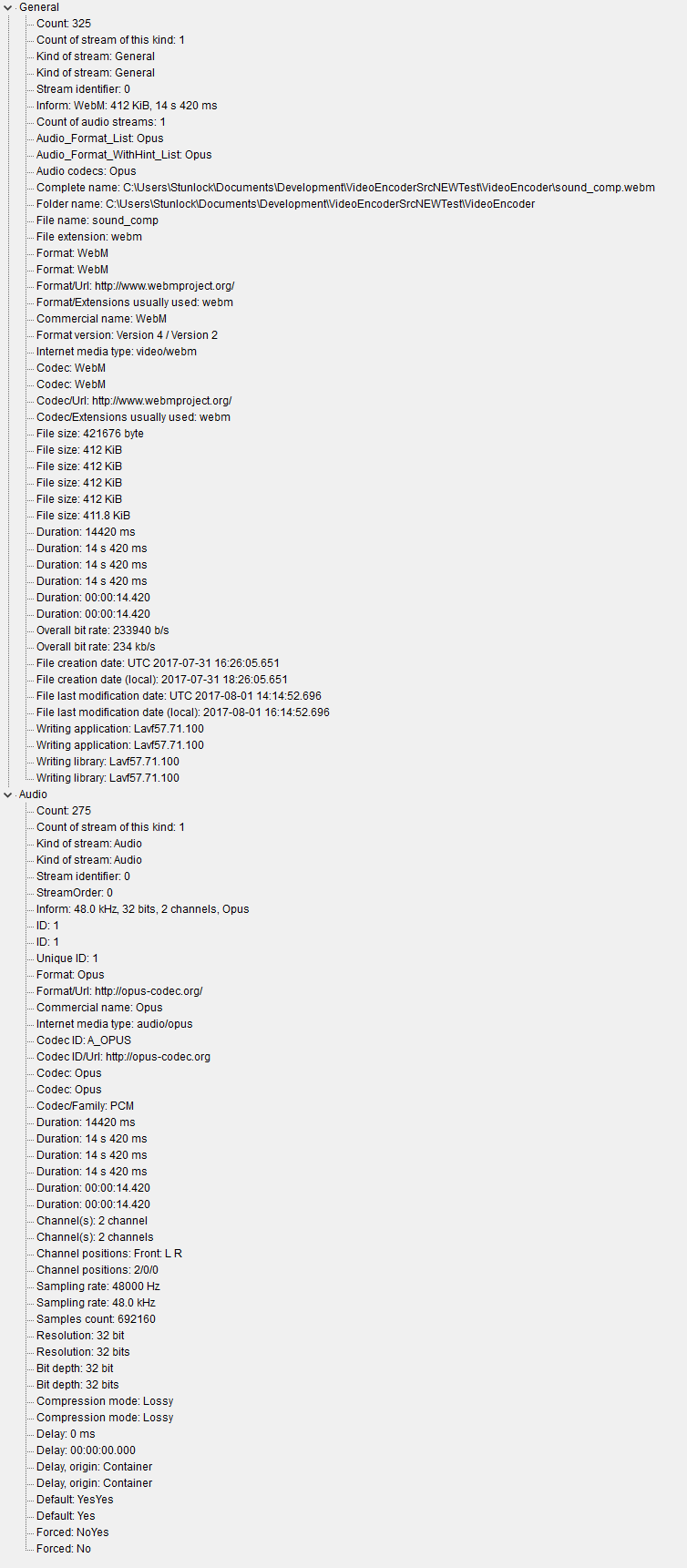
I’ve looked at the header with the "MediaInfo" app built in to MVKTool :
https://i.gyazo.com/3b29b41629a28bd526bf7637ce3f2601.png
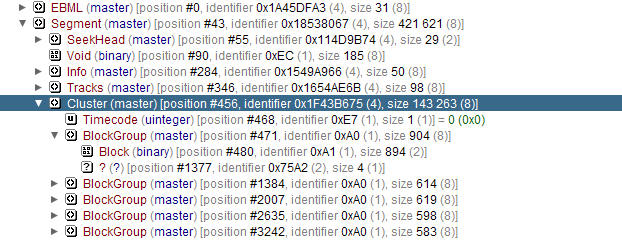
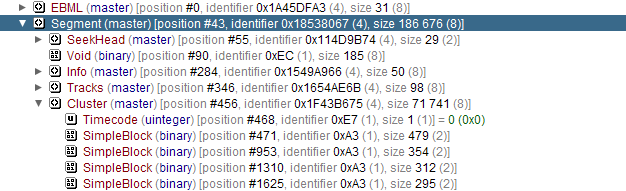
It all looks fine to me.I’ve also inspected the raw EBML file with EBML-Viewer (https://code.google.com/archive/p/ebml-viewer/) and in there I can se some difference between the files ;
My file : https://i.gyazo.com/6fa8c540a2698a8a4d3421d363aede0a.png
File produced with ffmpeg.exe : https://i.gyazo.com/04d60e64ff3c3040ea83e98cdf507530.pngIn my file it’s "Cluster" -> "BlockGroup" -> "Block", " ?"
In the other it’s just "Cluster" -> "SimpleBlock"
And in the webm specs, it says both are supported (https://www.webmproject.org/docs/container/)But I do not know much about these specific things, just looking for anything.



{kind=link}
{kind=link}
{kind=link}