Recherche avancée
Médias (1)
-

Géodiversité
9 septembre 2011, par ,
Mis à jour : Août 2018
Langue : français
Type : Texte
Autres articles (64)
-
Initialisation de MediaSPIP (préconfiguration)
20 février 2010, parLors de l’installation de MediaSPIP, celui-ci est préconfiguré pour les usages les plus fréquents.
Cette préconfiguration est réalisée par un plugin activé par défaut et non désactivable appelé MediaSPIP Init.
Ce plugin sert à préconfigurer de manière correcte chaque instance de MediaSPIP. Il doit donc être placé dans le dossier plugins-dist/ du site ou de la ferme pour être installé par défaut avant de pouvoir utiliser le site.
Dans un premier temps il active ou désactive des options de SPIP qui ne le (...) -
Installation en mode ferme
4 février 2011, parLe mode ferme permet d’héberger plusieurs sites de type MediaSPIP en n’installant qu’une seule fois son noyau fonctionnel.
C’est la méthode que nous utilisons sur cette même plateforme.
L’utilisation en mode ferme nécessite de connaïtre un peu le mécanisme de SPIP contrairement à la version standalone qui ne nécessite pas réellement de connaissances spécifique puisque l’espace privé habituel de SPIP n’est plus utilisé.
Dans un premier temps, vous devez avoir installé les mêmes fichiers que l’installation (...) -
Formulaire personnalisable
21 juin 2013, parCette page présente les champs disponibles dans le formulaire de publication d’un média et il indique les différents champs qu’on peut ajouter. Formulaire de création d’un Media
Dans le cas d’un document de type média, les champs proposés par défaut sont : Texte Activer/Désactiver le forum ( on peut désactiver l’invite au commentaire pour chaque article ) Licence Ajout/suppression d’auteurs Tags
On peut modifier ce formulaire dans la partie :
Administration > Configuration des masques de formulaire. (...)
Sur d’autres sites (9049)
-
Revision 36982 : Certaines valeurs ne passent pas dans presets ... on améliore de ce coté ...
6 avril 2010, par kent1@… — LogCertaines valeurs ne passent pas dans presets ... on améliore de ce coté là
On affiche les boutons sous les documents même dans le cas d’un retour ajax -
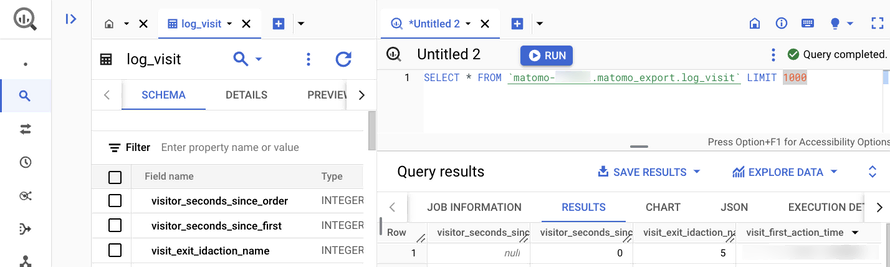
Introducing the Data Warehouse Connector feature
30 janvier, par Matomo Core Team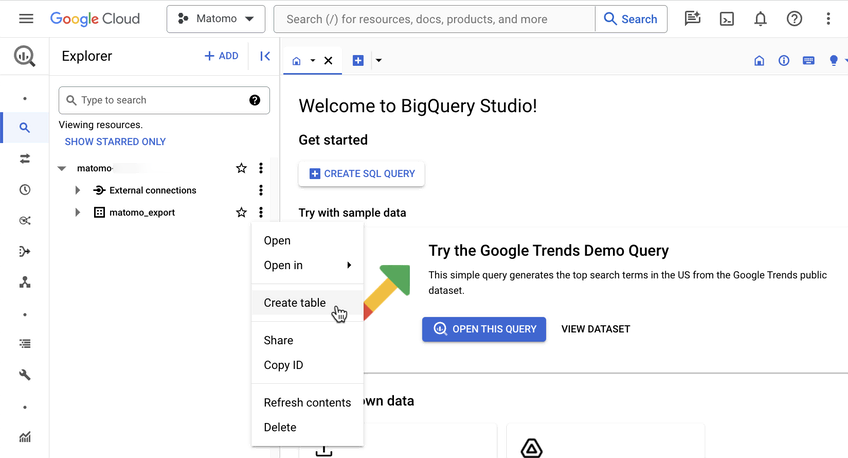
Try Matomo for Free
21 day free trial. No credit card required.
-
ffmpeg - Record Server Desktop Without Connection
21 janvier, par chrispI set up an application which uses ffmpeg to record a desktop on an Amazon AWS EC2 instance having Windows Server 2012 R2 installed. It records the desktop and puts the result into a file.



This works as long as a Remote Desktop or TeamViewer connection is active for that particular Amazon AWS EC2 instance. As soon as I close the Remote Desktop and TeamViewer connection the recording stops and continues as soon as I reconnect.



I assume that it's because the GPU doesn't deliver frames without a display in use.



How can I make sure that frames are constantly being rendered so that I can record them ?





