Recherche avancée
Médias (91)
-

Collections - Formulaire de création rapide
19 février 2013, par
Mis à jour : Février 2013
Langue : français
Type : Image
-

Les Miserables
4 juin 2012, par
Mis à jour : Février 2013
Langue : English
Type : Texte
-

Ne pas afficher certaines informations : page d’accueil
23 novembre 2011, par
Mis à jour : Novembre 2011
Langue : français
Type : Image
-

The Great Big Beautiful Tomorrow
28 octobre 2011, par
Mis à jour : Octobre 2011
Langue : English
Type : Texte
-

Richard Stallman et la révolution du logiciel libre - Une biographie autorisée (version epub)
28 octobre 2011, par
Mis à jour : Octobre 2011
Langue : English
Type : Texte
-

Rennes Emotion Map 2010-11
19 octobre 2011, par
Mis à jour : Juillet 2013
Langue : français
Type : Texte
Autres articles (68)
-
Personnaliser en ajoutant son logo, sa bannière ou son image de fond
5 septembre 2013, parCertains thèmes prennent en compte trois éléments de personnalisation : l’ajout d’un logo ; l’ajout d’une bannière l’ajout d’une image de fond ;
-
Ecrire une actualité
21 juin 2013, parPrésentez les changements dans votre MédiaSPIP ou les actualités de vos projets sur votre MédiaSPIP grâce à la rubrique actualités.
Dans le thème par défaut spipeo de MédiaSPIP, les actualités sont affichées en bas de la page principale sous les éditoriaux.
Vous pouvez personnaliser le formulaire de création d’une actualité.
Formulaire de création d’une actualité Dans le cas d’un document de type actualité, les champs proposés par défaut sont : Date de publication ( personnaliser la date de publication ) (...) -
Le profil des utilisateurs
12 avril 2011, parChaque utilisateur dispose d’une page de profil lui permettant de modifier ses informations personnelle. Dans le menu de haut de page par défaut, un élément de menu est automatiquement créé à l’initialisation de MediaSPIP, visible uniquement si le visiteur est identifié sur le site.
L’utilisateur a accès à la modification de profil depuis sa page auteur, un lien dans la navigation "Modifier votre profil" est (...)
Sur d’autres sites (6648)
-
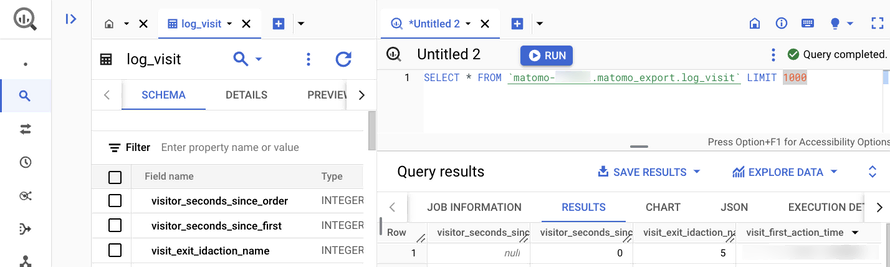
Introducing the Data Warehouse Connector feature
30 janvier, par Matomo Core Team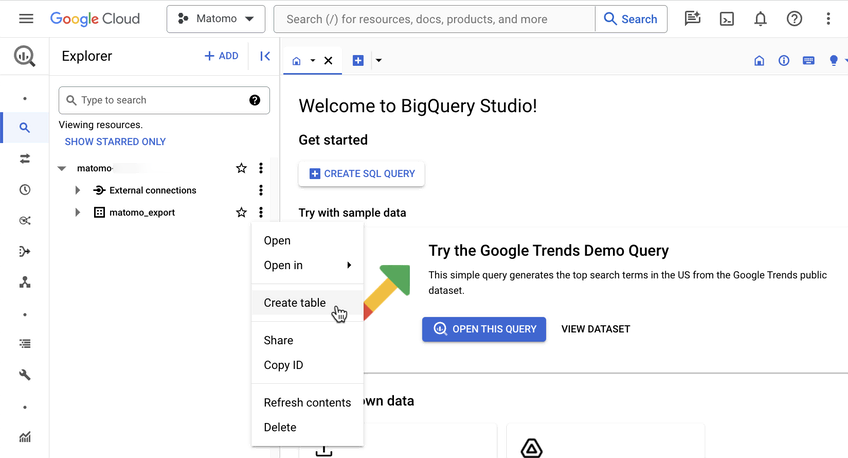
Try Matomo for Free
21 day free trial. No credit card required.
-
How can I build a custom version of opencv while enabling CUDA and opengl ? [closed]
10 février, par JoshI have a hard requirement of python3.7 for certain libraries (aeneas & afaligner). I've been using the regular opencv-python and ffmpeg libraries in my program and they've been working find.


Recently I wanted to adjust my program to use h264 instead of mpeg4 and ran down a licensing rabbit hole of how opencv-python uses a build of ffmpeg with opengl codecs off to avoid licensing issues. x264 is apparently opengl, and is disabled in the opencv-python library.


In order to solve this issue, I built a custom build of opencv using another custom build of ffmpeg both with opengl enabled. This allowed me to use the x264 encoder with the VideoWriter in my python program.


Here's the dockerfile of how I've been running it :



FROM python:3.7-slim

# Set optimization flags and number of cores globally
ENV CFLAGS="-O3 -march=native -ffast-math -flto -fno-fat-lto-objects -ffunction-sections -fdata-sections" \
 CXXFLAGS="-O3 -march=native -ffast-math -flto -fno-fat-lto-objects -ffunction-sections -fdata-sections" \
 LDFLAGS="-flto -fno-fat-lto-objects -Wl,--gc-sections" \
 MAKEFLAGS="-j\$(nproc)"

# Combine all system dependencies in a single layer
RUN apt-get update && apt-get install -y --no-install-recommends \
 build-essential \
 cmake \
 git \
 wget \
 unzip \
 yasm \
 pkg-config \
 libsm6 \
 libxext6 \
 libxrender-dev \
 libglib2.0-0 \
 libavcodec-dev \
 libavformat-dev \
 libswscale-dev \
 libavutil-dev \
 libswresample-dev \
 nasm \
 mercurial \
 libnuma-dev \
 espeak \
 libespeak-dev \
 libtiff5-dev \
 libjpeg62-turbo-dev \
 libopenjp2-7-dev \
 zlib1g-dev \
 libfreetype6-dev \
 liblcms2-dev \
 libwebp-dev \
 tcl8.6-dev \
 tk8.6-dev \
 python3-tk \
 libharfbuzz-dev \
 libfribidi-dev \
 libxcb1-dev \
 python3-dev \
 python3-setuptools \
 libsndfile1 \
 libavdevice-dev \
 libavfilter-dev \
 libpostproc-dev \
 && apt-get clean \
 && rm -rf /var/lib/apt/lists/*

# Build x264 with optimizations
RUN cd /tmp && \
 wget https://code.videolan.org/videolan/x264/-/archive/master/x264-master.tar.bz2 && \
 tar xjf x264-master.tar.bz2 && \
 cd x264-master && \
 ./configure \
 --enable-shared \
 --enable-pic \
 --enable-asm \
 --enable-lto \
 --enable-strip \
 --enable-optimizations \
 --bit-depth=8 \
 --disable-avs \
 --disable-swscale \
 --disable-lavf \
 --disable-ffms \
 --disable-gpac \
 --disable-lsmash \
 --extra-cflags="-O3 -march=native -ffast-math -fomit-frame-pointer -flto -fno-fat-lto-objects" \
 --extra-ldflags="-O3 -flto -fno-fat-lto-objects" && \
 make && \
 make install && \
 cd /tmp && \
 # Build FFmpeg with optimizations
 wget https://ffmpeg.org/releases/ffmpeg-7.1.tar.bz2 && \
 tar xjf ffmpeg-7.1.tar.bz2 && \
 cd ffmpeg-7.1 && \
 ./configure \
 --enable-gpl \
 --enable-libx264 \
 --enable-shared \
 --enable-nonfree \
 --enable-pic \
 --enable-asm \
 --enable-optimizations \
 --enable-lto \
 --enable-pthreads \
 --disable-debug \
 --disable-static \
 --disable-doc \
 --disable-ffplay \
 --disable-ffprobe \
 --disable-filters \
 --disable-programs \
 --disable-postproc \
 --extra-cflags="-O3 -march=native -ffast-math -fomit-frame-pointer -flto -fno-fat-lto-objects -ffunction-sections -fdata-sections" \
 --extra-ldflags="-O3 -flto -fno-fat-lto-objects -Wl,--gc-sections" \
 --prefix=/usr/local && \
 make && \
 make install && \
 ldconfig && \
 rm -rf /tmp/*

# Install Python dependencies first
RUN pip install --no-cache-dir --upgrade pip setuptools wheel && \
 pip install --no-cache-dir numpy py-spy

# Build OpenCV with optimized configuration
RUN cd /tmp && \
 # Download specific OpenCV version archives
 wget -O opencv.zip https://github.com/opencv/opencv/archive/4.8.0.zip && \
 wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.8.0.zip && \
 unzip opencv.zip && \
 unzip opencv_contrib.zip && \
 mv opencv-4.8.0 opencv && \
 mv opencv_contrib-4.8.0 opencv_contrib && \
 rm opencv.zip opencv_contrib.zip && \
 cd opencv && \
 mkdir build && cd build && \
 cmake \
 -D CMAKE_BUILD_TYPE=RELEASE \
 -D CMAKE_C_FLAGS="-O3 -march=native -ffast-math -flto -fno-fat-lto-objects -ffunction-sections -fdata-sections" \
 -D CMAKE_CXX_FLAGS="-O3 -march=native -ffast-math -flto -fno-fat-lto-objects -ffunction-sections -fdata-sections -Wno-deprecated" \
 -D CMAKE_EXE_LINKER_FLAGS="-flto -fno-fat-lto-objects -Wl,--gc-sections" \
 -D CMAKE_SHARED_LINKER_FLAGS="-flto -fno-fat-lto-objects -Wl,--gc-sections" \
 -D CMAKE_INSTALL_PREFIX=/usr/local \
 -D ENABLE_FAST_MATH=ON \
 -D CPU_BASELINE_DETECT=ON \
 -D CPU_BASELINE=SSE3 \
 -D CPU_DISPATCH=SSE4_1,SSE4_2,AVX,AVX2,AVX512_SKX,FP16 \
 -D WITH_OPENMP=ON \
 -D OPENCV_ENABLE_NONFREE=ON \
 -D WITH_FFMPEG=ON \
 -D FFMPEG_ROOT=/usr/local \
 -D OPENCV_EXTRA_MODULES_PATH=/tmp/opencv_contrib/modules \
 -D PYTHON_EXECUTABLE=/usr/local/bin/python3.7 \
 -D PYTHON3_EXECUTABLE=/usr/local/bin/python3.7 \
 -D PYTHON3_INCLUDE_DIR=/usr/local/include/python3.7m \
 -D PYTHON3_LIBRARY=/usr/local/lib/libpython3.7m.so \
 -D PYTHON3_PACKAGES_PATH=/usr/local/lib/python3.7/site-packages \
 -D PYTHON3_NUMPY_INCLUDE_DIRS=/usr/local/lib/python3.7/site-packages/numpy/core/include \
 -D BUILD_opencv_python3=ON \
 -D INSTALL_PYTHON_EXAMPLES=OFF \
 -D BUILD_TESTS=OFF \
 -D BUILD_PERF_TESTS=OFF \
 -D BUILD_EXAMPLES=OFF \
 -D BUILD_DOCS=OFF \
 -D BUILD_opencv_apps=OFF \
 -D WITH_OPENCL=OFF \
 -D WITH_CUDA=OFF \
 -D WITH_IPP=OFF \
 -D WITH_TBB=OFF \
 -D WITH_V4L=OFF \
 -D WITH_QT=OFF \
 -D WITH_GTK=OFF \
 -D BUILD_LIST=core,imgproc,imgcodecs,videoio,python3 \
 .. && \
 make && \
 make install && \
 ldconfig && \
 rm -rf /tmp/*

# Set working directory and copy application code
WORKDIR /app

COPY requirements.txt .

RUN apt-get update && apt-get install -y --no-install-recommends ffmpeg

RUN pip install --no-cache-dir aeneas afaligner && \
 pip install --no-cache-dir -r requirements.txt

COPY . .

# Make entrypoint executable
RUN chmod +x entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]


My trouble now, is I've been considering running parts of my program on my GPU, it's creating graphics for a video after all. I have no idea how to edit my Dockerfile to make the opencv build run with CUDA enabled, every combination I try leads to issues.


How can I tell which version of CUDA, opencv and ffmpeg are compatible with python 3.7 ? I've tried so so many combinations and they all lead to different issues, I've asked various AI agents and they all flounder. Where can I find a reliable source of information about this ?


-
Zlib vs. XZ on 2SF
I recently released my Game Music Appreciation website. It allows users to play an enormous range of video game music directly in their browsers. To do this, the site has to host the music. And since I’m a compression bore, I have to know how small I can practically make these music files. I already published the results of my effort to see if XZ could beat RAR (RAR won, but only slightly, and I still went with XZ for the project) on the corpus of Super Nintendo chiptune sets. Next is the corpus of Nintendo DS chiptunes.
Repacking Nintendo DS 2SF
The prevailing chiptune format for storing Nintendo DS songs is the .2sf format. This is a subtype of the Portable Sound Format (PSF). The designers had the foresight to build compression directly into the format. Much of payload data in a PSF file is compressed with zlib. Since I already incorporated Embedded XZ into the player project, I decided to try repacking the PSF payload data from zlib -> xz.In an effort to not corrupt standards too much, I changed the ’PSF’ file signature (seen in the first 3 bytes of a file) to ’psf’.
Results
There are about 900 Nintendo DS games currently represented in my website’s archive. Total size of the original PSF archive, payloads packed with zlib : 2.992 GB. Total size of the same archive with payloads packed as xz : 2.059 GB.Using xz vs. zlib saved me nearly a gigabyte of storage. That extra storage doesn’t really impact my hosting plan very much (I have 1/2 TB, which is why I’m so nonchalant about hosting the massive MPlayer Samples Archive). However, smaller individual files translates to a better user experience since the files are faster to download.
Here is a pretty picture to illustrate the space savings :
The blue occasionally appears to dip below the orange but the data indicates that xz is always more efficient than zlib. Here’s the raw data (comes in vanilla CSV flavor too).
Interface Impact
So the good news for the end user is that the songs are faster to load up front. The downside is that there can be a noticeable delay when changing tracks. Even though all songs are packaged into one file for download, and the entire file is downloaded before playback begins, each song is individually compressed. Thus, changing tracks triggers another decompression operation. I’m toying the possibility of some sort of background process that decompresses song (n+1) while playing song (n) in order to help compensate for this.I don’t like the idea of decompressing everything up front because A) it would take even longer to start playing ; and B) it would take a huge amount of memory.
Corner Case
There was at least one case in which I found zlib to be better than xz. It looks like zlib’s minimum block size is smaller than xz’s. I think I discovered xz to be unable to compress a few bytes to a block any smaller than about 60-64 bytes while zlib got it down into the teens. However, in those cases, it was more efficient to just leave the data uncompressed anyway.



