Recherche avancée
Autres articles (75)
-
(Dés)Activation de fonctionnalités (plugins)
18 février 2011, parPour gérer l’ajout et la suppression de fonctionnalités supplémentaires (ou plugins), MediaSPIP utilise à partir de la version 0.2 SVP.
SVP permet l’activation facile de plugins depuis l’espace de configuration de MediaSPIP.
Pour y accéder, il suffit de se rendre dans l’espace de configuration puis de se rendre sur la page "Gestion des plugins".
MediaSPIP est fourni par défaut avec l’ensemble des plugins dits "compatibles", ils ont été testés et intégrés afin de fonctionner parfaitement avec chaque (...) -
Activation de l’inscription des visiteurs
12 avril 2011, parIl est également possible d’activer l’inscription des visiteurs ce qui permettra à tout un chacun d’ouvrir soit même un compte sur le canal en question dans le cadre de projets ouverts par exemple.
Pour ce faire, il suffit d’aller dans l’espace de configuration du site en choisissant le sous menus "Gestion des utilisateurs". Le premier formulaire visible correspond à cette fonctionnalité.
Par défaut, MediaSPIP a créé lors de son initialisation un élément de menu dans le menu du haut de la page menant (...) -
Les tâches Cron régulières de la ferme
1er décembre 2010, parLa gestion de la ferme passe par l’exécution à intervalle régulier de plusieurs tâches répétitives dites Cron.
Le super Cron (gestion_mutu_super_cron)
Cette tâche, planifiée chaque minute, a pour simple effet d’appeler le Cron de l’ensemble des instances de la mutualisation régulièrement. Couplée avec un Cron système sur le site central de la mutualisation, cela permet de simplement générer des visites régulières sur les différents sites et éviter que les tâches des sites peu visités soient trop (...)
Sur d’autres sites (8135)
-
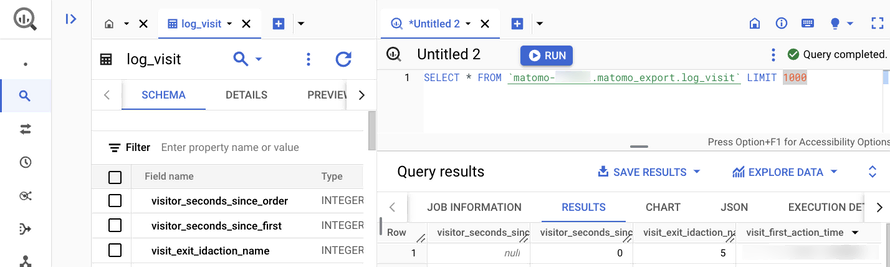
Introducing the Data Warehouse Connector feature
30 janvier, par Matomo Core Team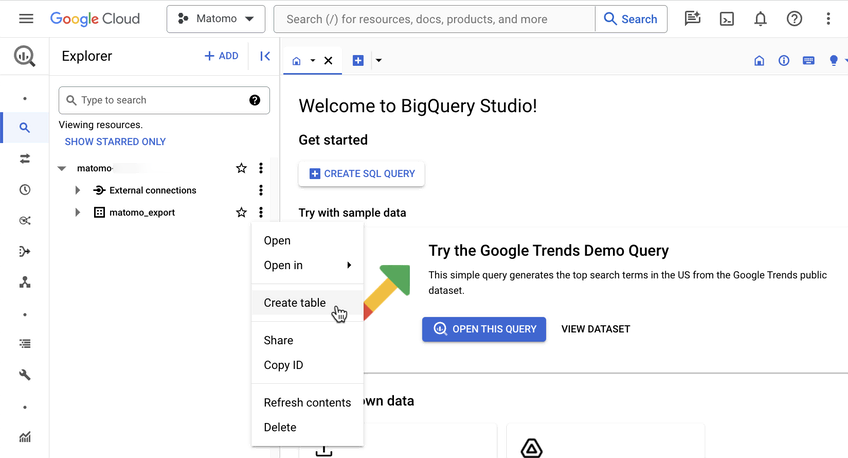
Try Matomo for Free
21 day free trial. No credit card required.
-
ffmpeg - Record Server Desktop Without Connection
21 janvier, par chrispI set up an application which uses ffmpeg to record a desktop on an Amazon AWS EC2 instance having Windows Server 2012 R2 installed. It records the desktop and puts the result into a file.



This works as long as a Remote Desktop or TeamViewer connection is active for that particular Amazon AWS EC2 instance. As soon as I close the Remote Desktop and TeamViewer connection the recording stops and continues as soon as I reconnect.



I assume that it's because the GPU doesn't deliver frames without a display in use.



How can I make sure that frames are constantly being rendered so that I can record them ?


-
ffmpeg not working with filenames that have whitespace
1er avril 2017, par cmwI’m using FFMPEG to measure the duration of videos stored in an Amazon S3 Bucket.
I’ve read the FFMPEG docs, and they explicitly state that all whitespace and special characters need to be escaped, in order for FFMPEG to handle them properly :
See docs 2.1 and 2.1.1 : https://ffmpeg.org/ffmpeg-utils.html
However, when dealing with files whose filenames contain whitespace, ffmpeg fails to render a result.
I’ve tried the following, with no success
ffmpeg -i "http://s3.mybucketname.com/videos/my\ video\ file.mov" 2>&1 | grep Duration | awk '{print $2}' | tr -d
ffmpeg -i "http://s3.mybucketname.com/videos/my video file.mov" 2>&1 | grep Duration | awk '{print $2}' | tr -d
ffmpeg -i "http://s3.mybucketname.com/videos/my'\' video'\' file.mov" 2>&1 | grep Duration | awk '{print $2}' | tr -d
ffmpeg -i "http://s3.mybucketname.com/videos/my\ video\ file.mov" 2>&1 | grep Duration | awk '{print $2}' | tr -dHowever, if I strip out the whitespace in the filename – all is well, and the duration of the video is returned.
Any help is appreciated !



